使用Excel进行逻辑回归预测-Kaggle泰坦尼克案例
背景介绍:
因为工作需要进行一些数据预测的工作,对于比较简单的预测可以用线性回归来做,Excel就自带线性回归的公式,点击几下就可以达到结果,比较简单,对于比较复杂的预测就需要用逻辑回归来进行预测
什么是线性回归:
线性回归解决变量是线性的数字,且预测结果是具体的数字,如根据各个渠道的广告费和销售额进行线性回归,拿到线性回归公式后,就可以根据指定的渠道费用预测销售额
什么是逻辑回归:
对于预测结果是分类的数据如根据一个人的特征指标如是否熬夜,是否压力大,年龄,抽烟喝酒状况预测一个人是60岁以后是否会得癌症以及根据一个邮件的标题,内容,称呼,发送时间,发送邮箱来预测一份邮件是否是垃圾邮件,对于这种根据一些特征指标(有的为具体数字如年纪,有的为类型如性别)预测结果为 是或者否的情况,我们需要使用逻辑回归来进行预测
逻辑回归怎么做:
对于逻辑回归,网上很多都是使用Python代码或者SPSS等专业软件来完成,但对于没有经验的小白或没有安装专业分析软件的,有没有一种能在Excel上操作, 像做线性回归那样点击几次鼠标就能轻松拿到结果
我先用百度查询了下逻辑回归excel的关键词,基本上很少,就算用excel也要使用复杂的公式来计算,然后谷歌搜索,使用英文 excel logistic regression,终于找到国外大神的办法,不需要什么懂公式,不需要编程, 点击几次按钮既可完成复杂的逻辑回归预测
案例介绍:
本文以excel插件(Robert Nau,美国杜克大学教授,为MBA课程开发)结合kaggle上(全球公认顶级有80万数据科学家进行机器学习竞赛的平台)网站上的案例-泰坦尼克号幸存者及遇难者名单, 使用幸存人员特征进行逻辑回归预测,找到具备如何特征的人会在这场灾难中有更高的存活率
操作步骤:
Excel插件,推荐使用
https://regressit.com/regressitlogistic.html(再次感谢Robert Nau,美国杜克大学教授)
(备选工具,http://www.real-statistics.com/free-download/)
软件截图如下

1,工具准备-Excel具体的插件安装方法
1.1下载逻辑回归插件文件xlam

需要注意它有很多版本,我们需要下载的是带有逻辑回归,mac也可以下载
访问网站https://regressit.com/regressitlogistic.html
1.2,从Excel导入逻辑回归插件
点击excel按钮,点击选项

再弹出的选项窗口 选择add-in,然后选择goto

1.3 导入插件到excel库中
再打开插件的目录,把我们下载的xlam的插件放入这个目录中
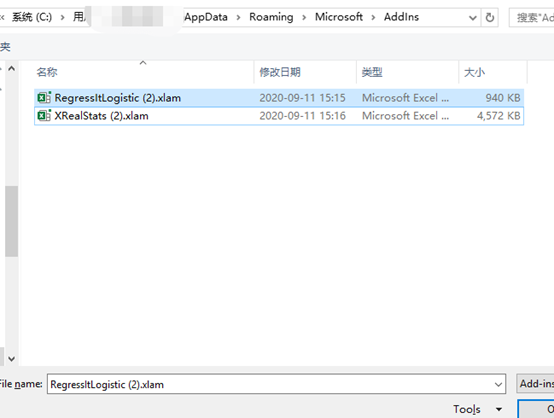
1.4安装完成预览
在顶部tab位置可以看到 regressit的窗口,其中logistic regression就是我们用的功能

2,数据准备-kaggle案例数据下载及整理
2.1 访问kaggle网站下载样本数据
访问kaggle上泰坦尼克的案例网站
https://www.kaggle.com/c/titanic/data
按截图所示选择数据,train.csv
里面存放了样本数据(891个真实人员的身份信息及最终是否存活)

2.2使用插件选择数据区域及命名变量
使用excel打开样本数据train.csv后,选择插件后,先点击 选择数据 以及创建名称

•PassengerID(ID)
•Survived(存活与否)
•Pclass(客舱等级,较为重要)
•Name(姓名,可提取出更多信息)
•Sex(性别,较为重要)
•Age(年龄,较为重要)
•Parch(直系亲友)
•SibSp(旁系)
•Ticket(票编号)
•Fare(票价)
•Cabin(客舱编号)
•Embarked(上船的港口编号)
2.3 确认变量名称位置
点创建名称位置,选择top row,既使用第一行的名称做为变量的名称(有的数据名称写在第一列,就可以点击left column)

2.4 确定特征值与预测值对应关系
点击logstic regression 进行预测设置,主要是设置非独立变量(dependent,既别人影响的变量)为Survived这列,则独立变量(independent 自变量,能影响到别人的变量,特征值))
要选中分类表和roc曲线

2.5点击运行预览模型结果

这里要说明的几个选项
2.5.1 P-value说明每一个参数的可信度,要小于0.05,越小越好,理解为这个参数失误的可能性

2.5.2 percent correct,预测准确率,既预测的数据里面猜对的比例,(猜对分2种,预测死亡,实际死亡,和预测生存实际也生存)

2.5.3 true positive rate,正确召回率,既猜中生存的(预测活,实际活的人数) 除以所有活下来的人数,既能找回多少比例活的人,或者根据预测结果,能把实际活下来的人找到的比例
2.5.4 true negative rate,错误找回率,既猜中死亡(预测死,实际死的人数)除以所有死的人的数字,既能召回多少比例死的人,或者根据预测结果,能把实际死亡的人找到的比例
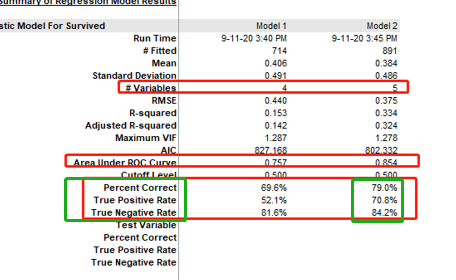
2.5.5 ROC曲线,0.76,既然整个公式预测的拟合度,你可以理解衡量整个公式正确率的数据,越接近1 越好,可以理解为公式的正确率吧
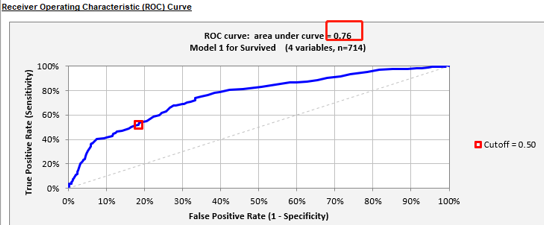
从截图数据看到,这里的正确召回率特别低 只有52%,意味着只能把幸存者中的52%给预测出来,所以这数据还是不怎么行

起码3个率(正确率,和2类情况下的召回率),都要80%以上
3,模型优化-优化参数 提升预测准确率
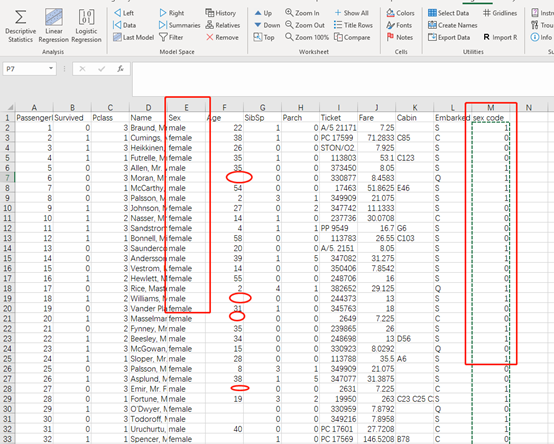
3.1 增加辅助变量 -性别信息进行数字化
这里考虑加上性别这个变量,因为电影里面船长说 让女人和小孩先走,所以性别应该会有结果有影响,然后我们看到有些人是没有年龄的数据的,需要 把缺失的数据补全
对于性别,因为逻辑回归工具只能识别数字,所以需要把男性都变成1,女性都变成0,既生成一个辅助列M,当为男性的时候 M列 Sex code为1, 反之为0
对于F列 年龄,对于缺失值,使用整个F列平均值补齐
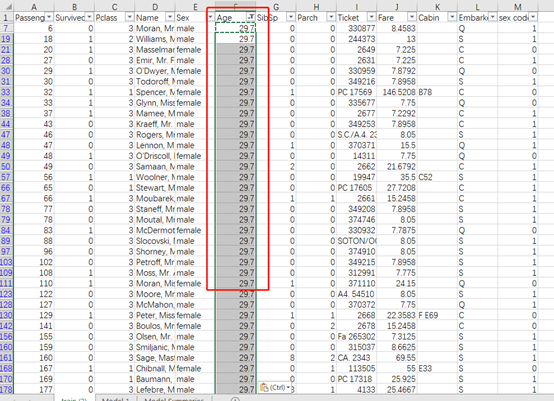
3.2 优化先有变量-补齐缺失值
对于缺失的某些人群的特征值,使用29.7 这个平均值补齐
3.3 从新配置逻辑回归变量
重新选择变量(增加了1个变量),点击select data,再创建名称
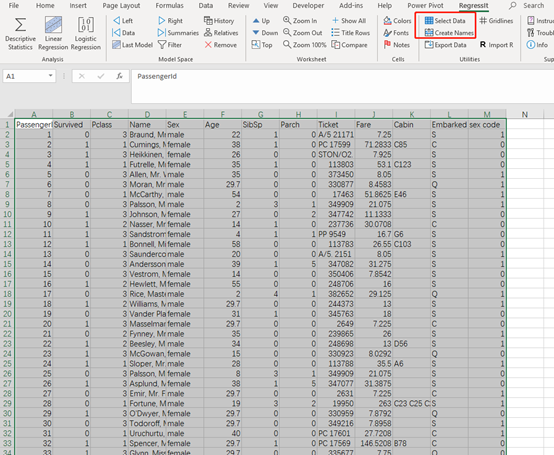
再弹出的窗口可以看到变成模型2,且可以选择独立变量既sex code这个新增加的变量
其他选择和之前保持一致
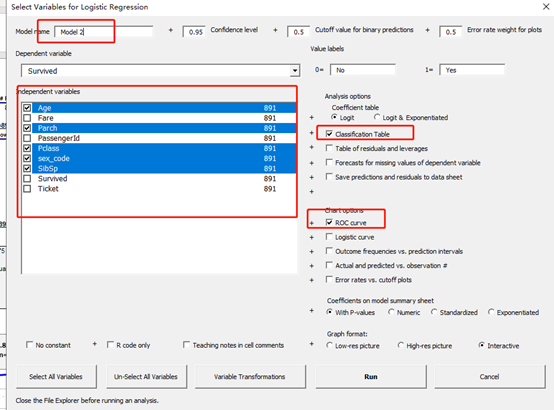
3.4 点击运行的到新结果
这次的结果中,ROC 有0.85,比之前高,且3个率 也比之前有比较大提升,认为模型2比模型1要好
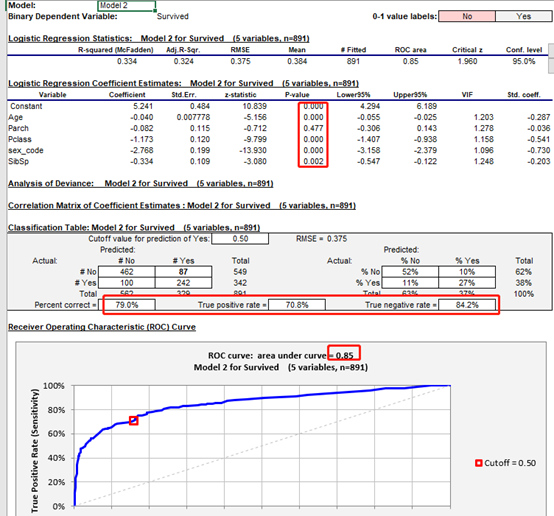
3.6 多模型对比 选优
可以点击excel中新增的对比模型的表格可以清楚看到2个模型的差距
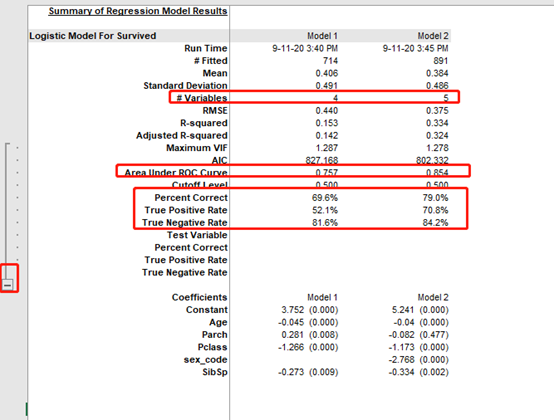
变量数由4变成5

然后不同模型的ROC值和3个率
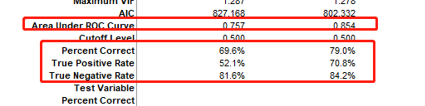
以及P值(扩后内是每个变量的P值) 括号外 是每个变量的系数,后面会用到
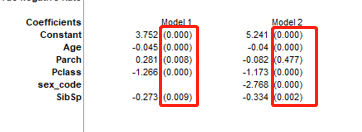
4,预测结果检验-预测公式整理及数据验证
通过上述2个模型,我们可以使用模型2进行预测,这里我们可以把模型2的公式进行
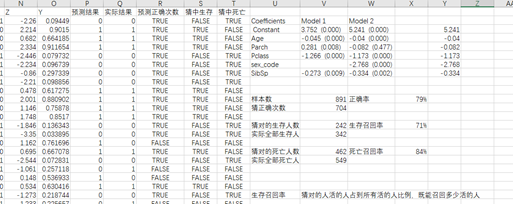
这里看到模型2最重要数据是4个参数,分别是对应变量的权重
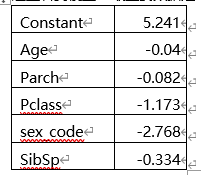
既常数是5.241, 年龄的系数是-0.04 其他同理
那么我们可以计算出一个Z值,既使用每行里面的特征值乘以对应的权重,如下图,使用第2行这个人的各自的属性值乘以对应系数进行相加 得到Z值,
如第3行的人的Z值是2.214
第4行的人的Z值是0.682
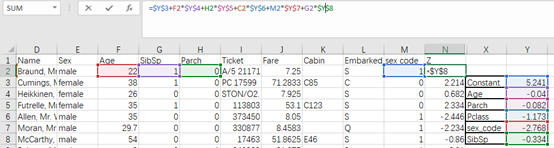
.
为了最终能的到发生存活的概率(0-1)这样的值,我们需要使用公式将Z值进行变化,既无论Z值为什么值,最后Y值都是在0-1之间)使用线性回归转逻辑回归公式
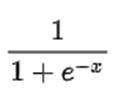
这样的X就使用Z值进行替代
就的到Y值,如下图,Z值为-2.26,经过公式替换就变成y=0.09449
表示这个人的幸存概率不到10%, 接合我们前面的定义,大于50%的概率我们认为会幸存,所以这个人预测结果就是0, 代表遇难, 如果是1就是幸存,同时我们可以看到实际结果也确实为0,为遇难,所以我们增加一列预测正确次数,为true,既我们猜对了,公式为当都是0(预测是0,实际也是0,或者预测是1 实际是1)那么R列为预测正确,然后我们再区分猜中幸存的统计在S列,既猜1,且实际为1, 和猜中遇难(预测是0,实际是0)
那么就可以统计正确率,生存召回率及死亡找回率
与我们之前算的结果一致
这样我们就算能精确计算每一个存活的概率和判断最终是否幸存的结论
5,获取新数据进行验证,参加比赛
我们可以从kaggle里面再下载新的数据(之前给的是部分样本数据)
https://www.kaggle.com/c/titanic/data?select=test.csv
下载test数据
在test.csv的新的数据中,和之前的样本数据一致,但是没有结果指标,既没有是否遇难,我们可以根据之前的公式,就可以预测了.
最终输出下面的预测结果,id号和预测结果
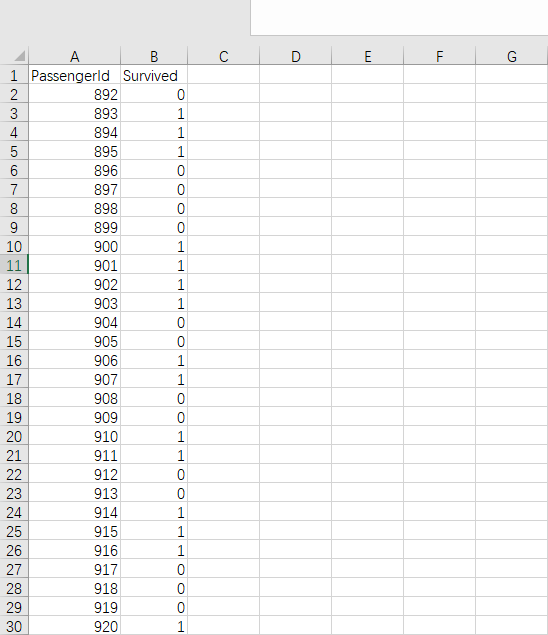
然后上传到网页上就可以比赛 获得排名
排名不高,可以忽略
结语:
本文详细记录了Excel使用插件进行逻辑回归的办法,同时也例举了Kaggle上下载数据和进行预测,并参加比赛的办法
附上数据表格
results