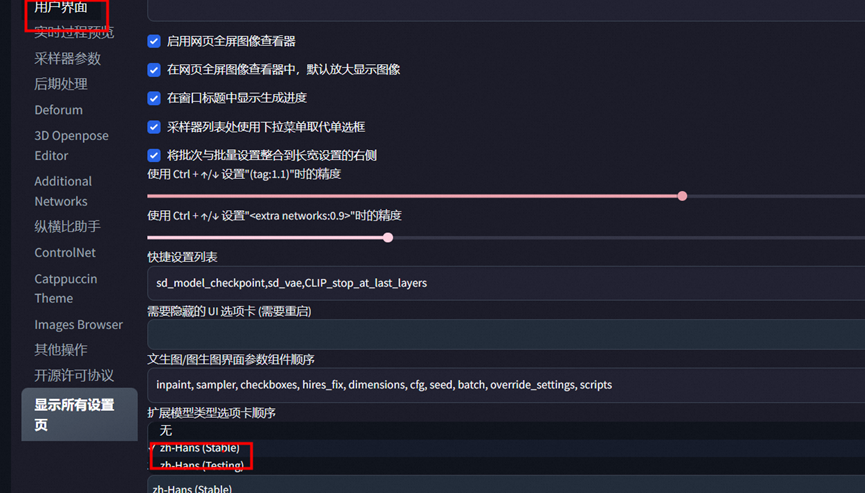
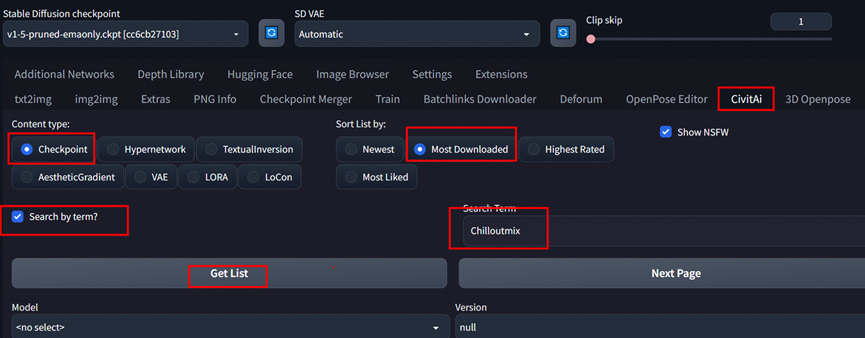
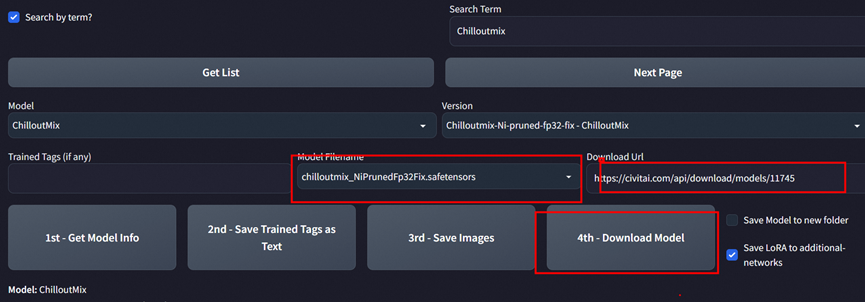
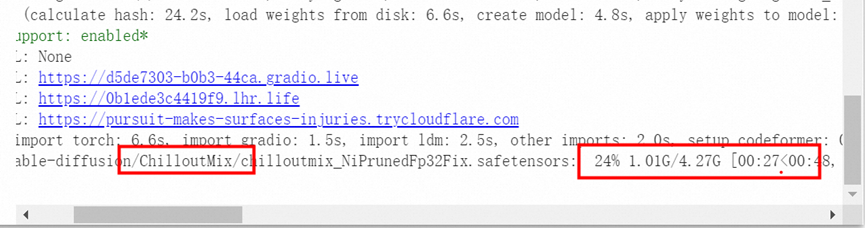
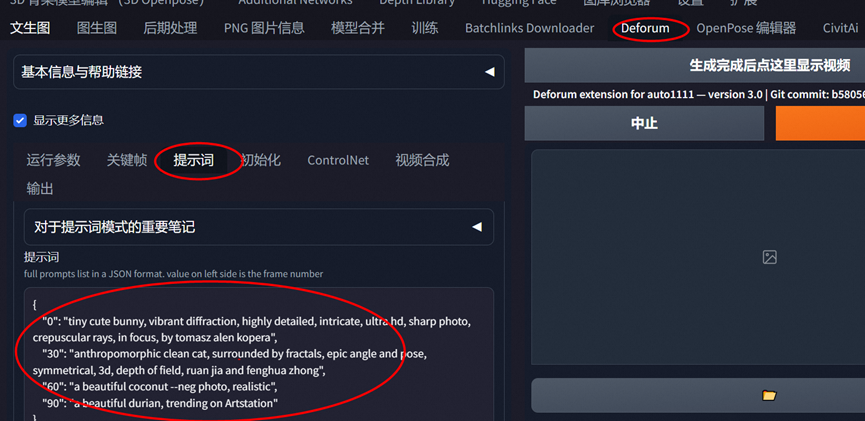
背景:
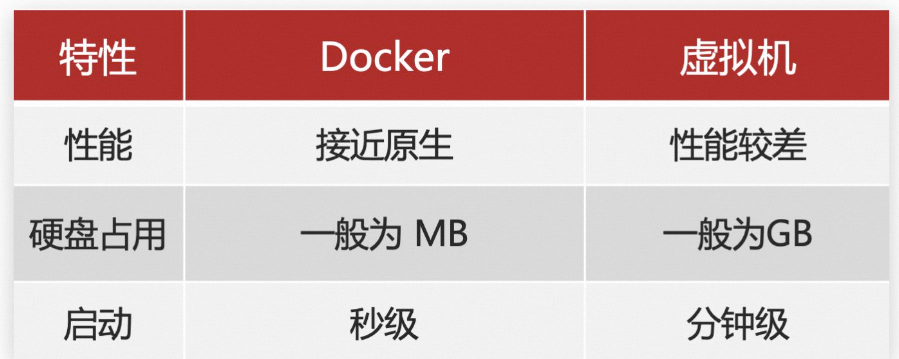
目前市面上的chatgpt产品很多,以国外非开源的chatgpt 为主的,优势就是强大,速度快,逻辑能力强
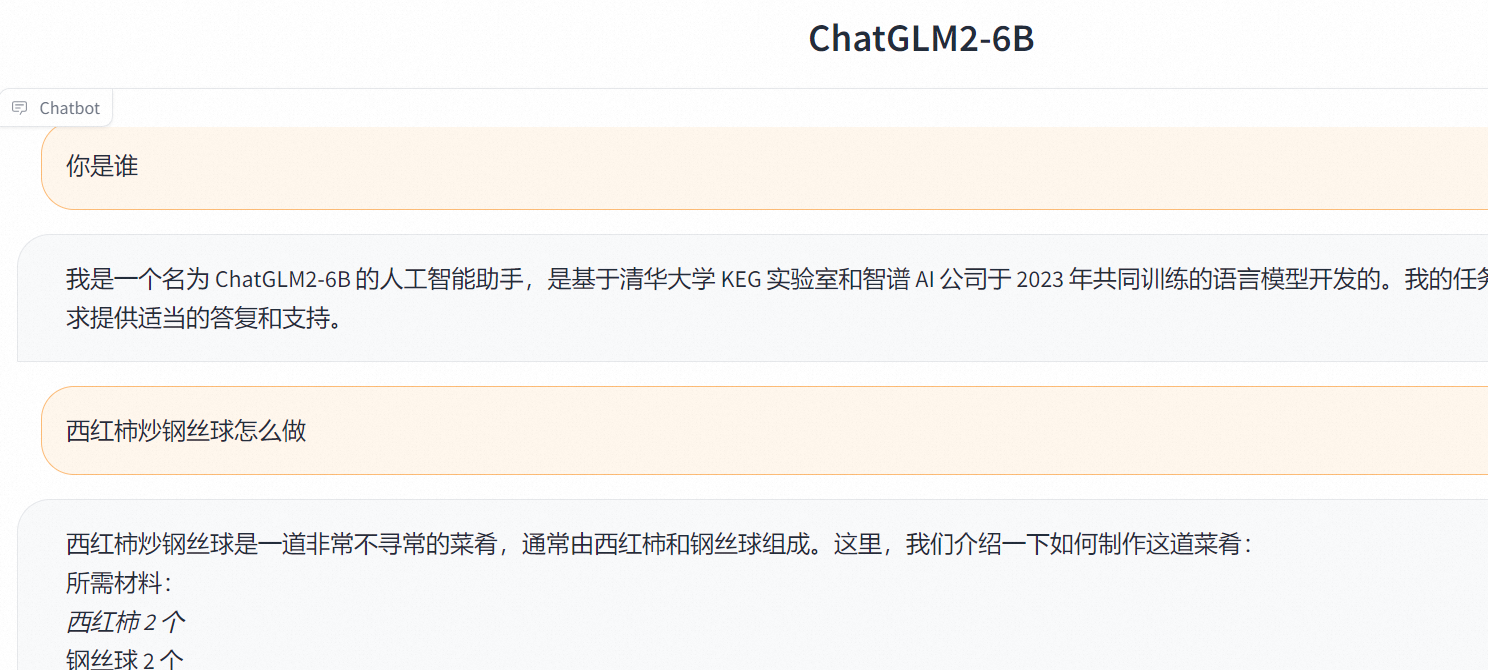
国内也有各大厂商做的非开源的,但是目前唯一开源的清华大学的chatglm 是可以直接在本地电脑上使用,避免了数据泄露的问题以及合规性的问题,本文主要是通过谷歌的colab体验下chatglm2-6b的部署运行方法
1,在google colab上新建代码
https://colab.research.google.com/#create=true
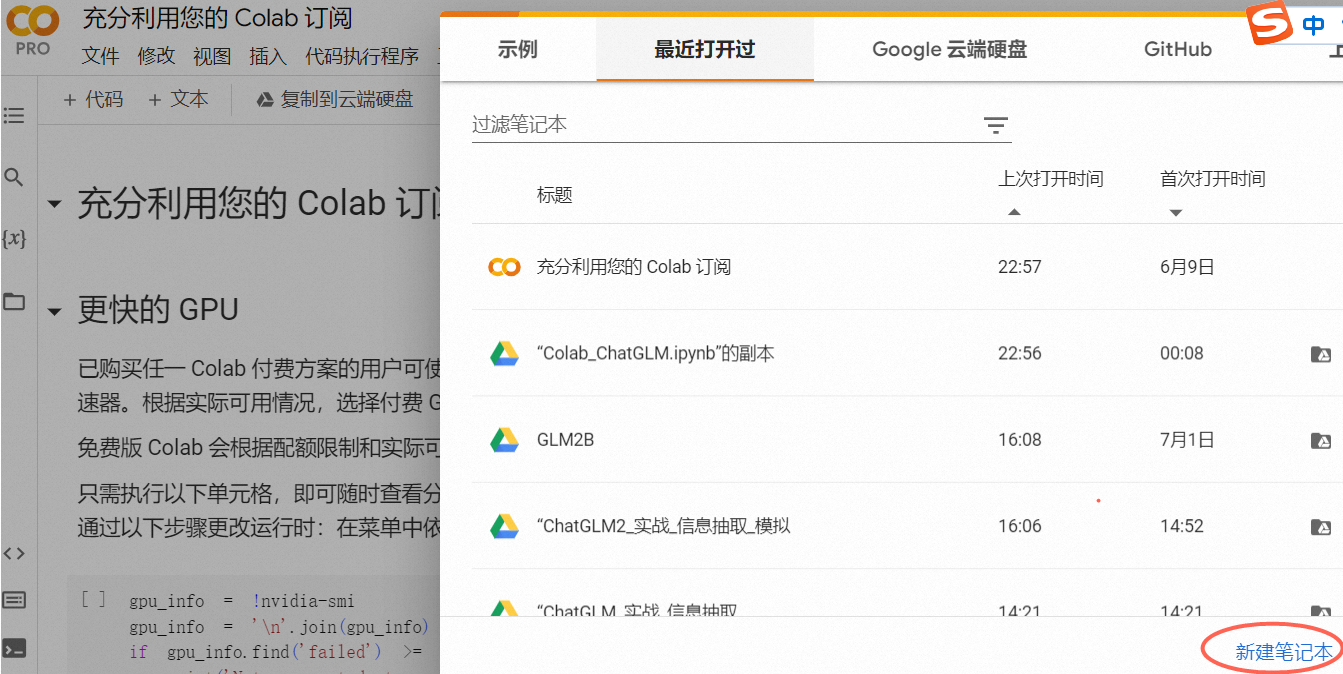
2,修改文件名称以及运行的gpu配置(更快)
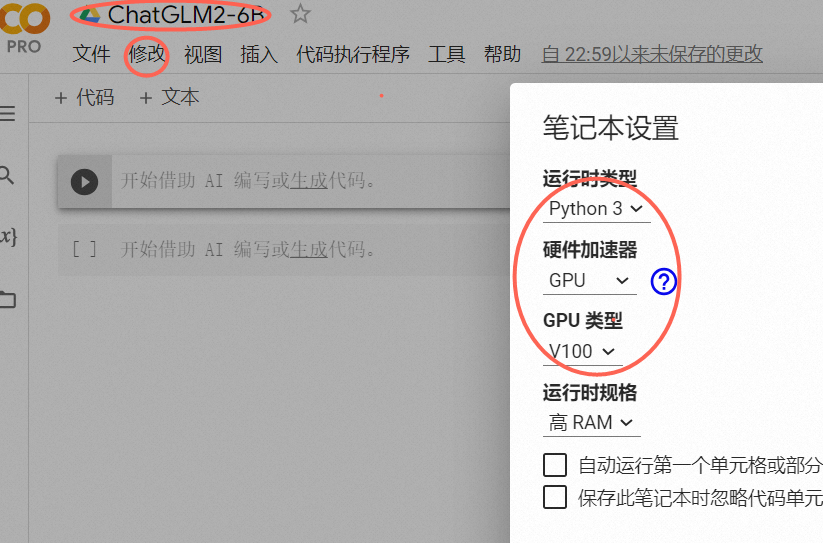
3,连接服务商 点击右上角
4,输入代码
可以通过点击红框位置 增加不同的代码快
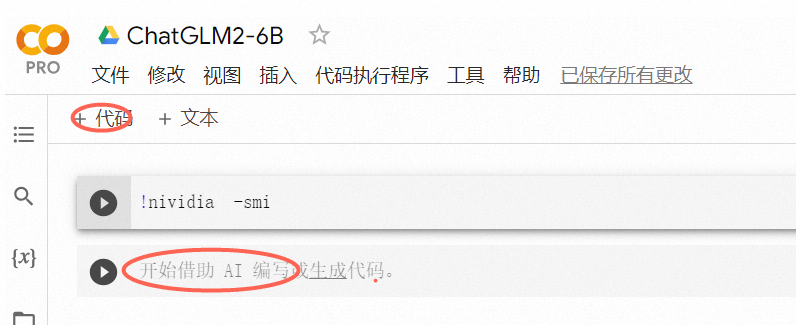
6 输入以下4行代码
!nvidia -smi
!git clone https://github.com/THUDM/ChatGLM2-6B
!pip install -r /content/ChatGLM2-6B/requirements.txt
!python /content/ChatGLM2-6B/web_demo.py
分别解释下,第一行 !nvidia -smi 代表检查当前的显卡类型
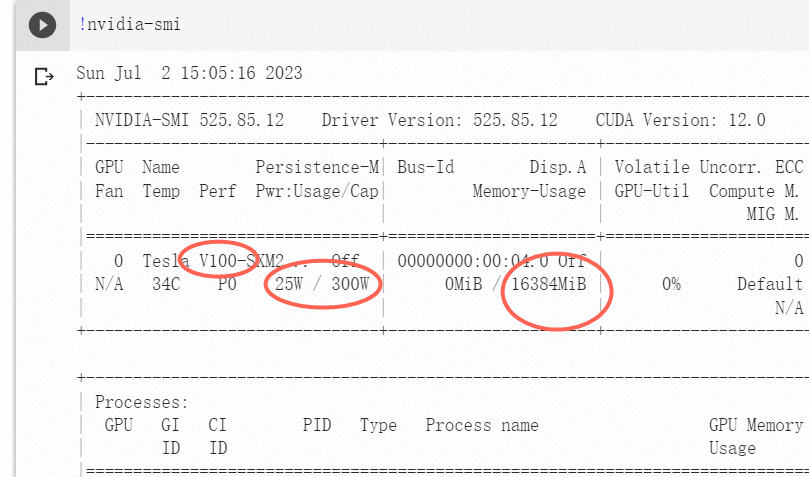
点击代码左侧的按钮可以看到运行结果,选择的是v100显卡,功率最大300w,有16g显存
这个显卡的性能决定了大模型的速度,非常重要,遗憾的是如果免费版的google colab只能选择t4类型的显卡 虽然也是16g显存 但是功率要小 的多
2,!git clone https://github.com/THUDM/ChatGLM2-6B
这个命令是将github上的源代码复制到本地
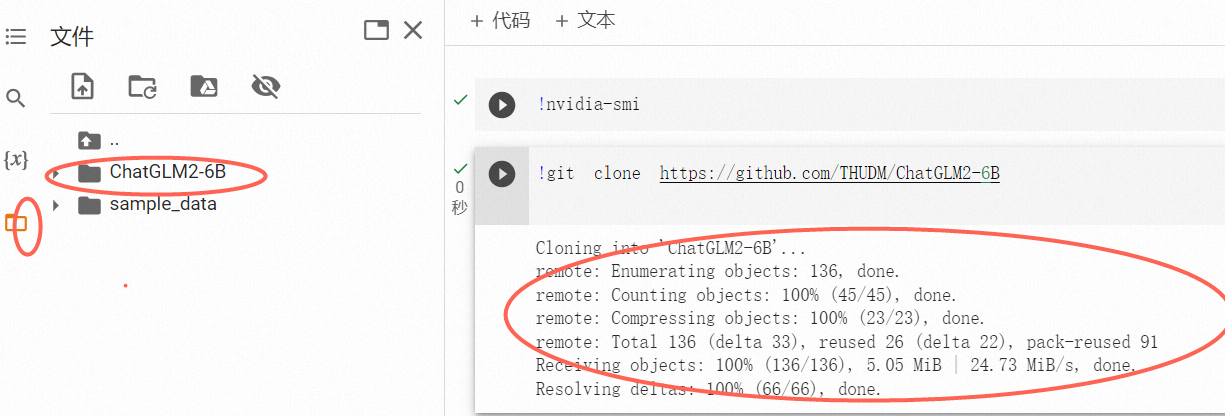
可以看到 文件中多了一个文件夹 就是把github上的chatglm2-6b复制到本地
3.!pip install -r /content/ChatGLM2-6B/requirements.txt
这个是安装包 将chatglm2-6b需要的库进行安装
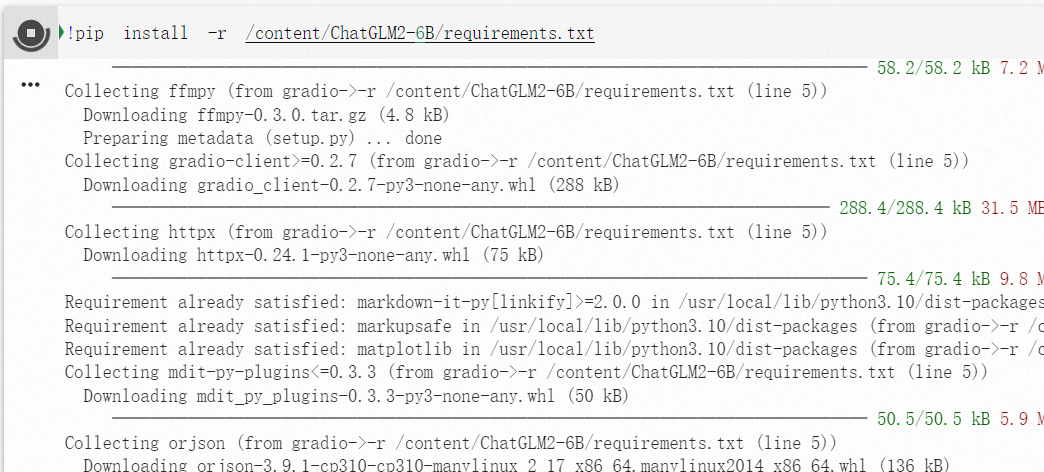
因为这个是一个复杂的软件工程,需要很多依赖的函数库,所以都打包在requirement里面
写清楚了需要运行的环境,使用pip就是python的安装包,可以根据函数名称 进行安装
-r 代表以只读方法打开, install 就是安装
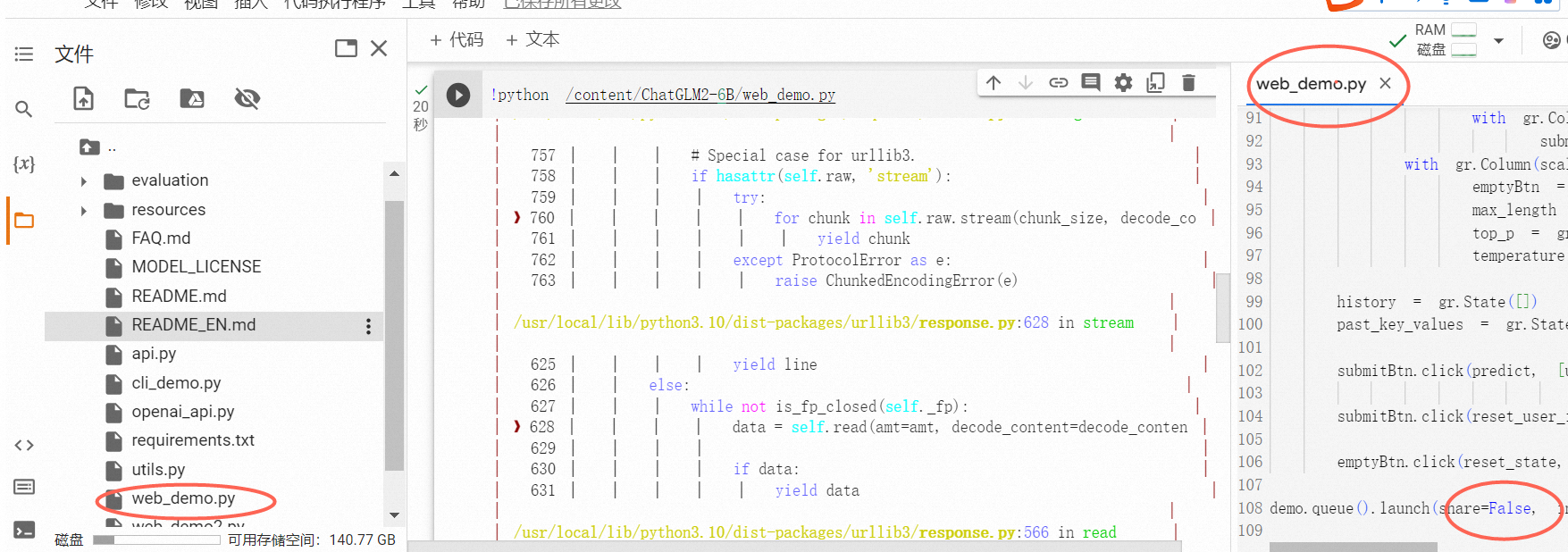
5,修改参数
需要先打开web_demo.py 将参数修改
把share的参数从False改成True 这样就会生成公网的连接
6
运行最后的web demo文件
!python /content/ChatGLM2-6B/web_demo.py
这是最后一步,
这是全部代码(
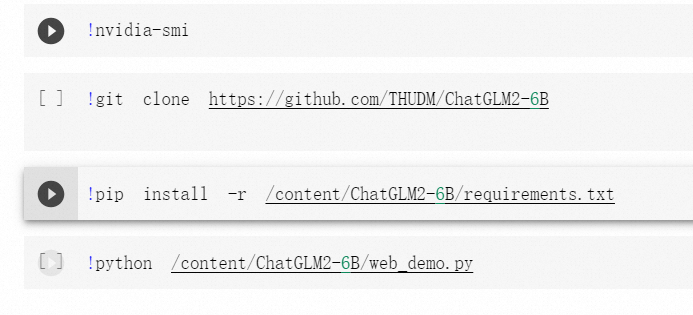
最后生产的网址就可以访问了