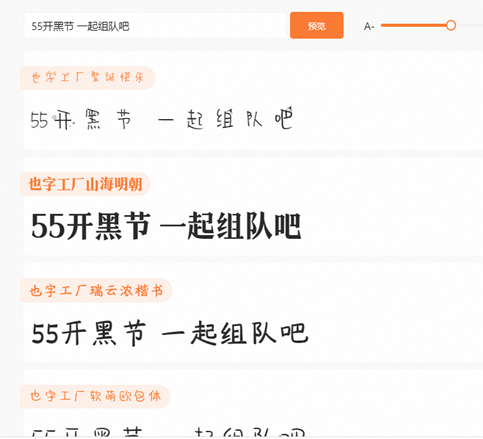
背景:
目前在AIGC领域,除了chatgpt这种文字生成工具以外,还有midjounery和stable diffusion这样的图片生成工具,前者是一种标准化的产品,输入promote就可以直接输出,后者属于定制化的产品,结合很多插件和模型,可以精确定制你的头像,但是stable diffusion是需要进行安装和耗费服务器资源,所以一般对所用电脑有限制,需要使用GPU资源,目前比较高档的超过5000块钱的显卡才能跑的动比较成熟的模型,所以通过云服务商来运行资源就是比较性价比高的选择
目前国内有阿里云国外有谷歌云都有云计算服务提供算力,本文主要围绕通过谷歌云,google colab进行一步步拆解来讲解下如何使用谷歌云资源进行安装stable diffusion进行模型的安装和视频的制作
正文:
1,stable diffusion web版本源代码下载及安装在google colab
首先 stable diffusion有很多版本,最开始的命令行的版本,但是使用起来要记得繁琐的命令,现在有一种web界面,通过按钮和输入框来进行模型的调整,目前使用的最广的就是
stable diffusion webui colab
我们可以在github 搜索stable diffusion webui colab
https://github.com/search?q=stable%20diffusion%20webui%20colab&type=repositories
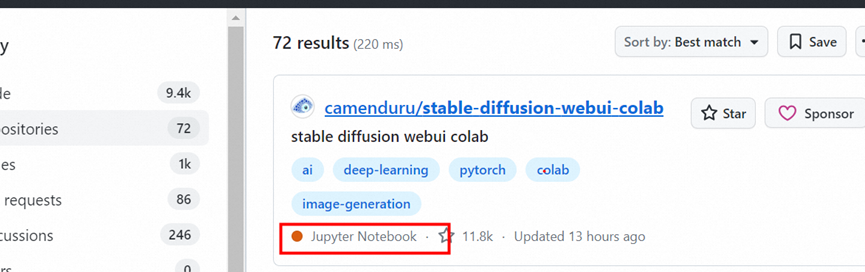
这是使用google的 colab进行 云部署
选择1.5版本的 stable 版本
点击后就跳转到google colab了
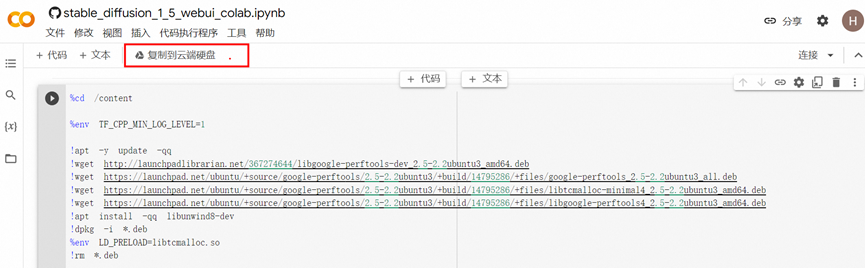
在google colab中,可以把安装代码先复制到云端硬盘,可以先选择保存 在修改下名字
,这样下次再次安装就不用打开
以上就把SD的安装代码复制到google 云上,但是这个代码很小只有几百行,与实际
2,选择运行模式,
因为不同的运行模式耗费不同的资源,有不同的价格()当然你也可以等1个小时出一个图),也而已选择付费购买计算资源,9美金以一个月,有100个计算资源,然后我对比看楼下 有3种GPU资源,T4的GPU 一小时用2个计算资源,那么可以用50个小时,一天22小时足够
如果换成V100,一小时是7.5个计算资源,那么只能用13小时,一天只能玩半小时,
如果换成A100,大名鼎鼎的最厉害的GPU,一小时是13个计算资源,只能用8小时,所以不到逼不得已,只需要v100 足够了,宝尊每天都可以玩半小时
选择使用gpu运行

最后的结论还是使用V100 比较好,每天都可以玩半小时, A100太烧钱
3,运行代码
这里使用选择全部运行
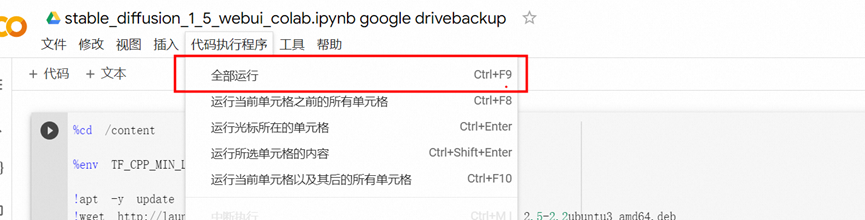
一路确认

然后就可以看到程序在运行
会慢慢下载SD的所有资源包
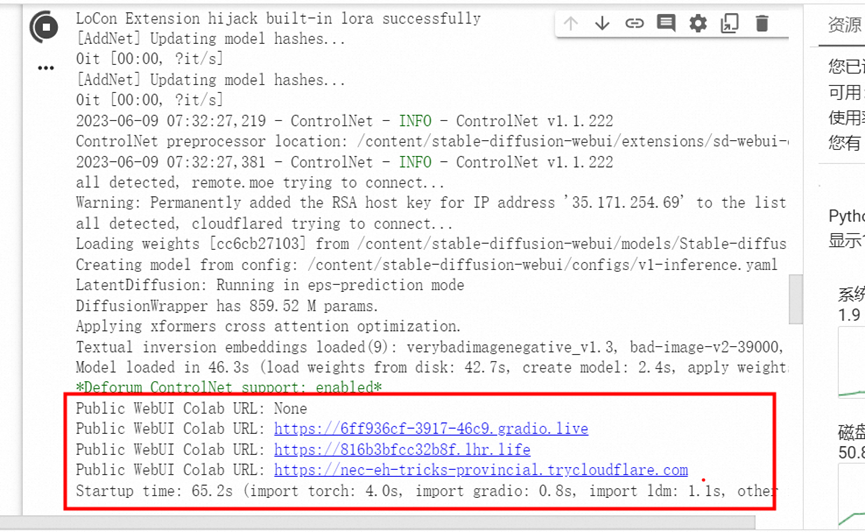
最后就可以看到这个网址出现 就是web界面的SD已经ready了
可以点击访问了
4, SD的简单配置
首先进行汉化
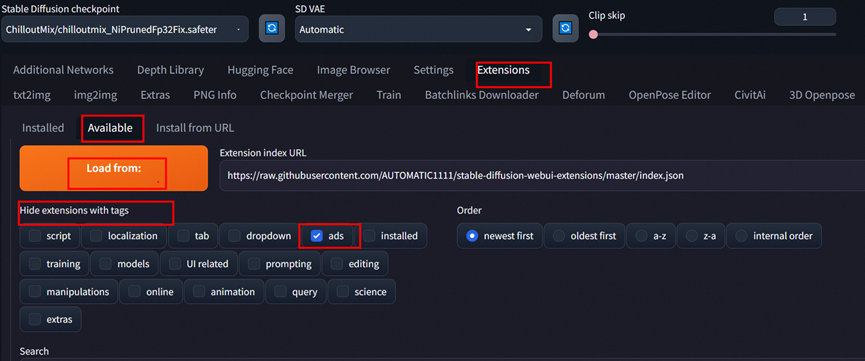
选择extention下 load 下 搜搜下zh
点安装, 在去setting下面的 user interface里面选好 就哈
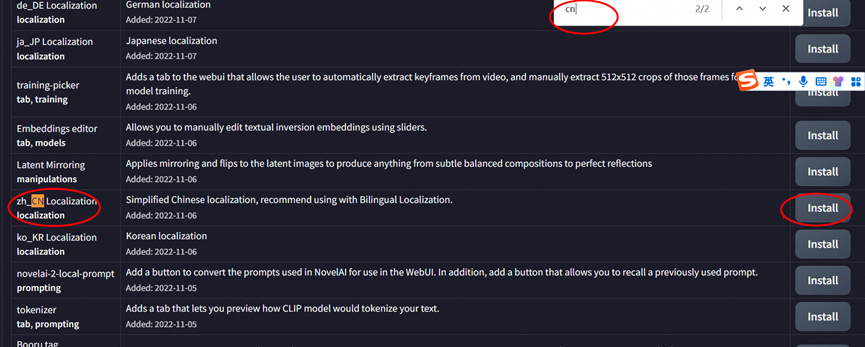
然后点击安装后,重新加载
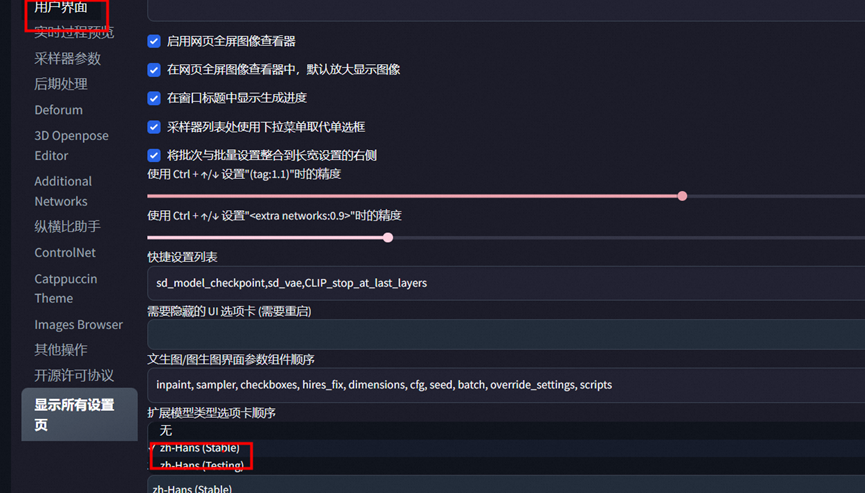
就可以完成汉化
2,安装小姐姐模型 chilloutmix
还需要下载专门的人物模型
如C站里面花小姐姐的 chilloutmix
https://civitai.com/models/6424/chilloutmix
选择Civiai 标签
内容类型选择checkpoint
排序选择
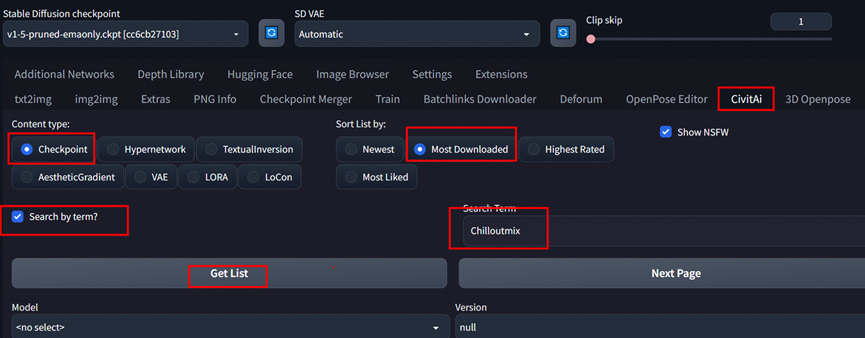
可以参考下面小红书教程
https://www.xiaohongshu.com/explore/641d807a0000000012033ff6
https://www.xiaohongshu.com/explore/6422cc1f000000001303cb6a
https://zhuanlan.zhihu.com/p/621472274
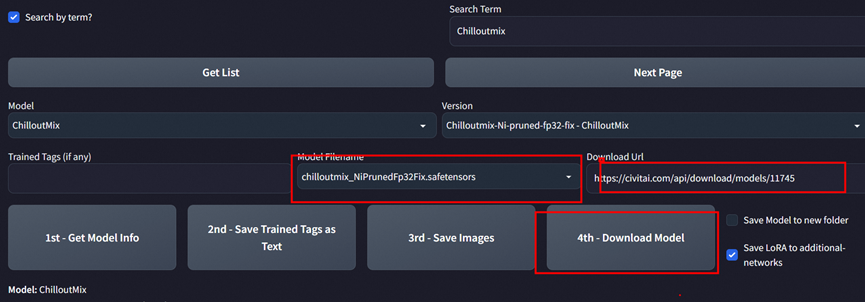
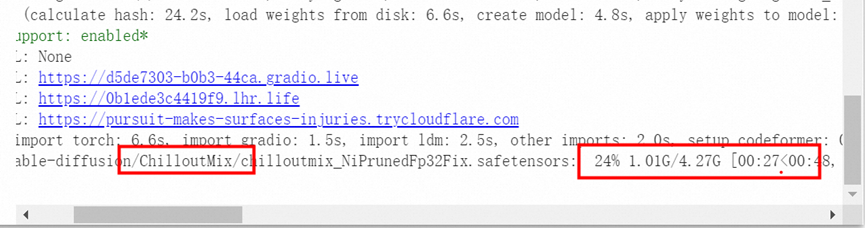
点击download 后就可以看到模型在下载
安装好后选择刷新,模型就可以看到chilloutmix这个模型
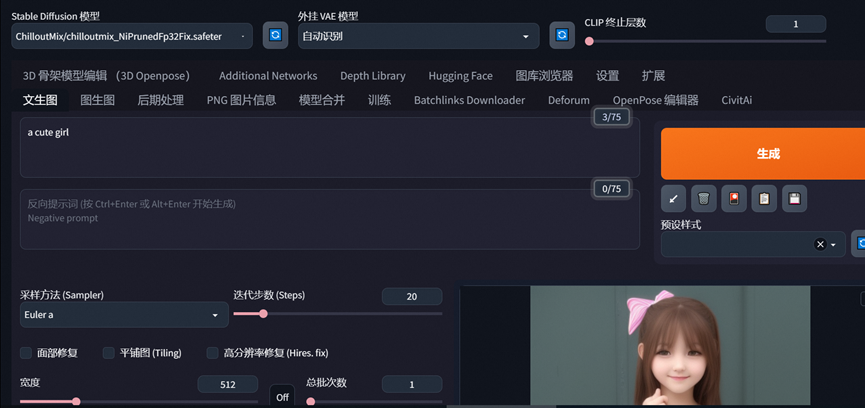
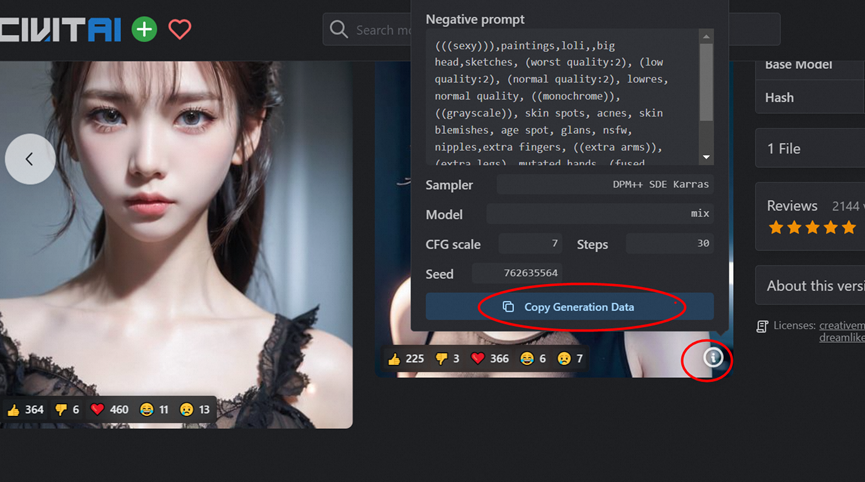
也可以上C占 复制下别人的代码 直接生成,会有惊喜
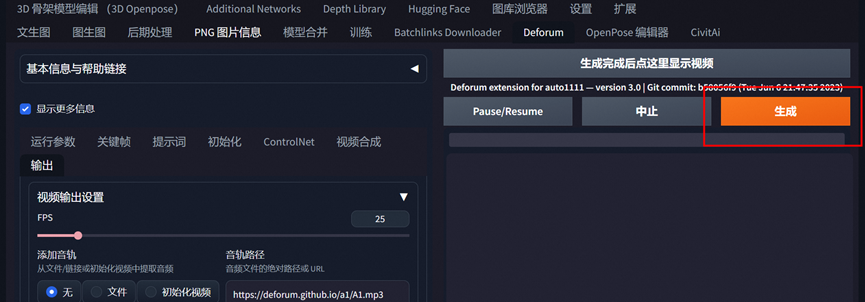
使用deforum制作视频
学做视频
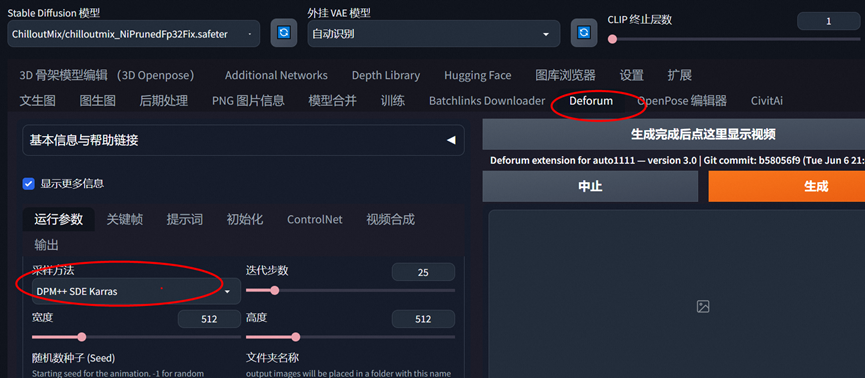
首先设置下面的采样方式业绩图片大小
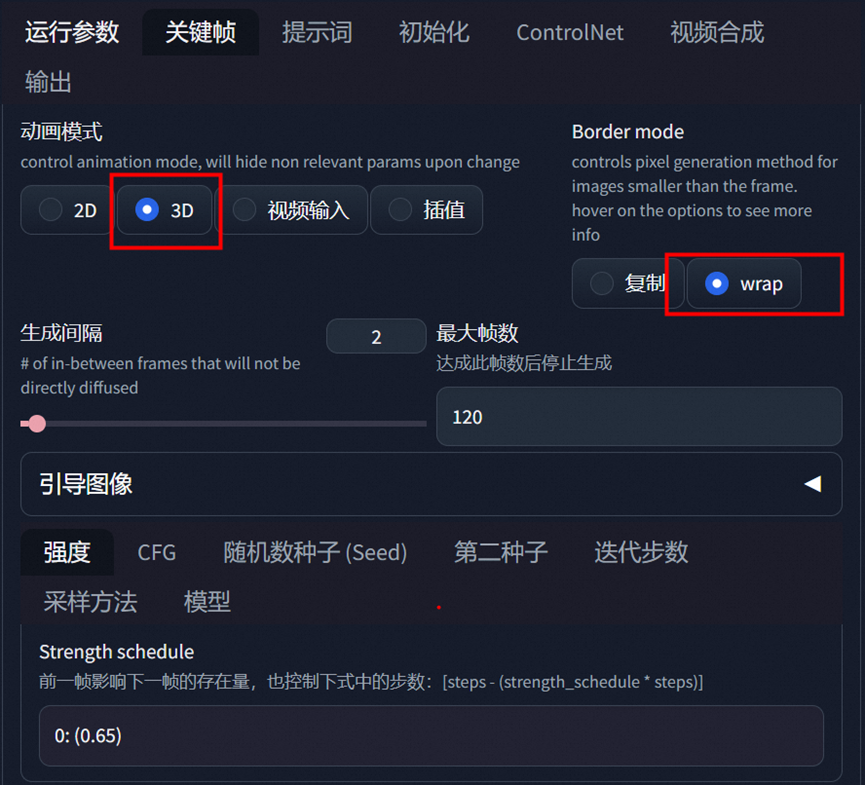
修复下面部
动画效果选3D 同时选wrap
提示词可以考虑使用
https://civitai.com/models/59785/deforum-chatgpt-prompter
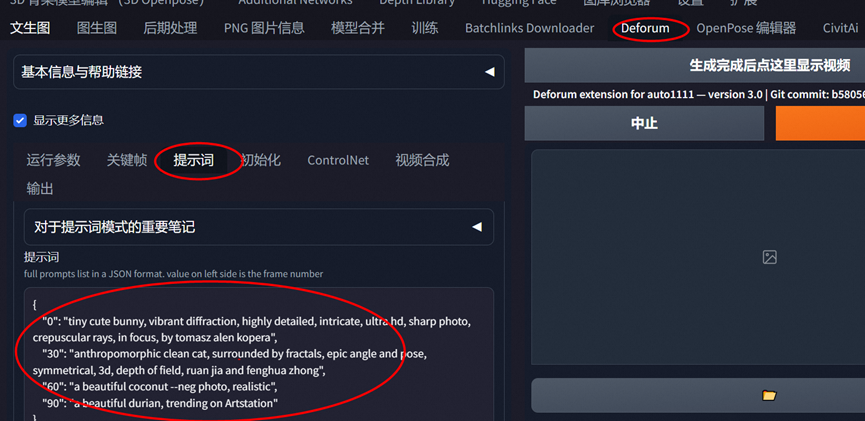
使用gpt来生成
输入咒语后,输入条件
a prompt about the rise and fall of a civillzation, 600 frames
以及
can you add more details, for example, add the human development process, from the Stone Age to the Steam Age,to the Age of Technology, to the Future Age of Technology and more.
对于初始图片可以用这个
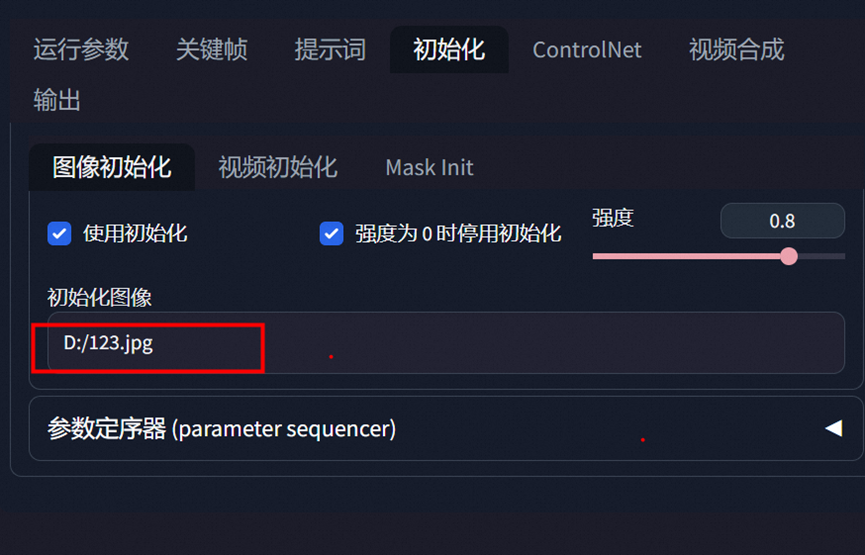
这里可以使用图片上传到云中
参考下面
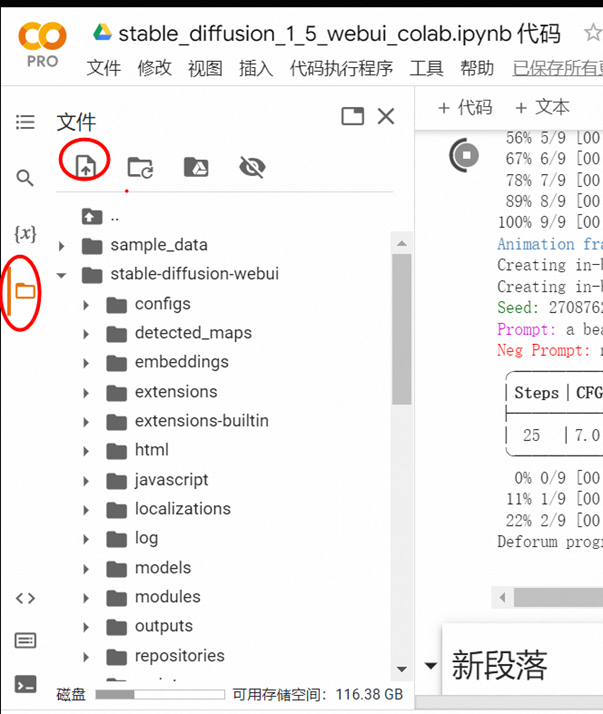
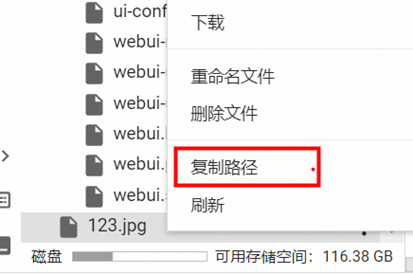
可以获得线上的图片地址
最后输出选项可以选择放大
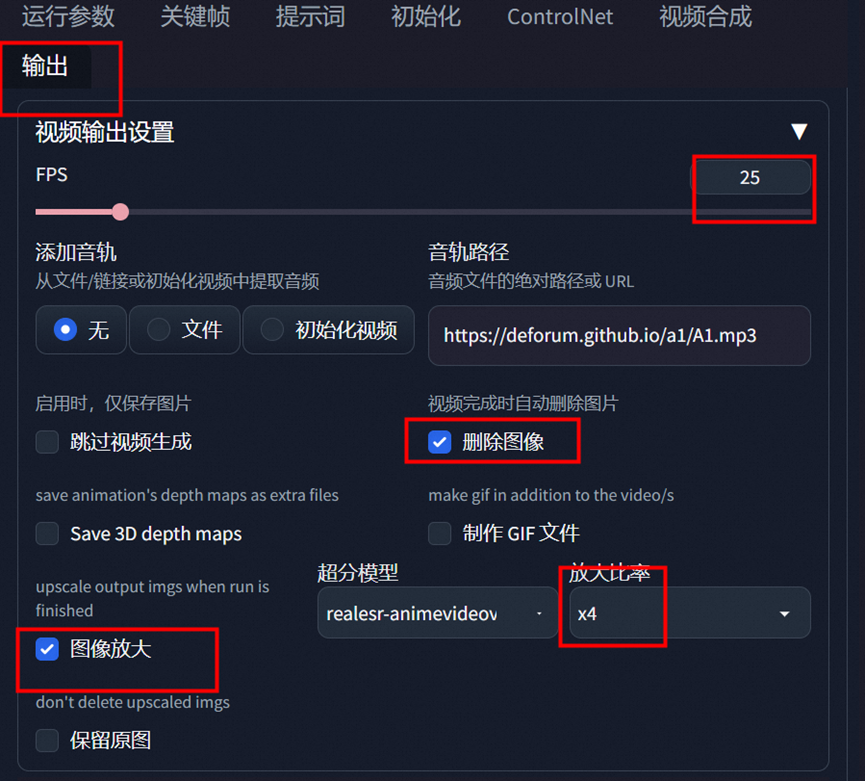
然后生成即可