背景: 因为工作需要找寻一些文章材料,国内的文章可能重复度比较高,需要比较创新原创的内容, 然后了解到国外的medium网址上有很多专家分享观点,只是因为是英文的,有一定理解难度,考虑比较简单的方法进行翻译,对比了chatgpt还有deepl以及百度翻译,最后觉得还是chatgpt能力更胜一筹
正文部分:
打开medium网站,可以看到她是创始人就是推特的创始人,主要是专业作家和业余作家分享观点,类似中国的知乎,只是汇聚的全球的专家
https://medium.com/tag/brand-strategy
选择一个标签,比如品牌策略,然后就可以看到所有被打标为品牌策略的文章 可以看到 只是一篇17小时之前发布的,绝对原创的文章,还可以看到作者的名字 可以看到文字的内容大概2页,500多字符

首先这里可以简单介绍下网页的内容复制到word的排版技巧,只需要3个步骤
轻松拿捏所有格式
1, 统一字体和大小
全选文字后选择
这样瞬间所有大小不一的文字都修改完毕
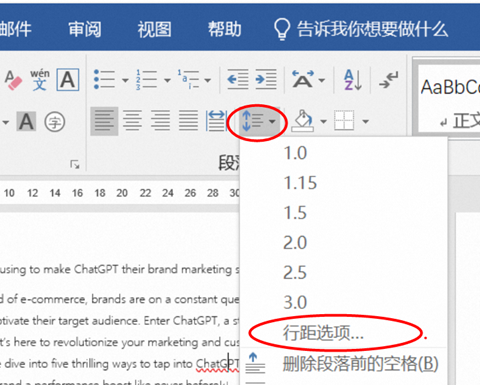
2, 调整行间距和段落间距
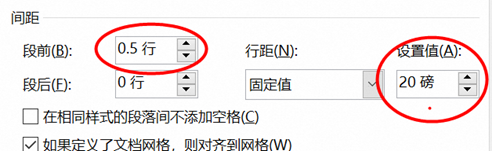
选择下面的菜单,行间距就是每一行之间的距离,设置固定值20,
段前距就是每个段落也就是回车键的间距,这里设置为0.5行
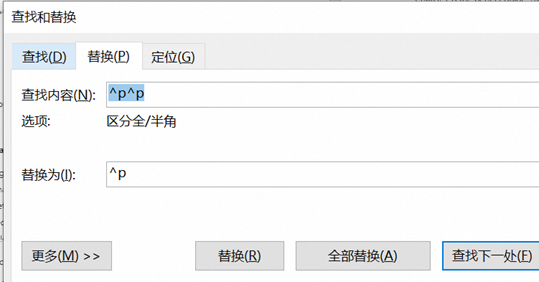
3, 批量替换多余的回车
因为有些段落中间空余了很多回车键,所有这里使用替换^p^P 这样的命令对超过2个以上的回车减半, 可以使用2次就可以把所有大幅的回车替换好
调整好英文文章以后,就是中文部分,可以使用deepl进行翻译
1,
https://www.deepl.com/translator/files
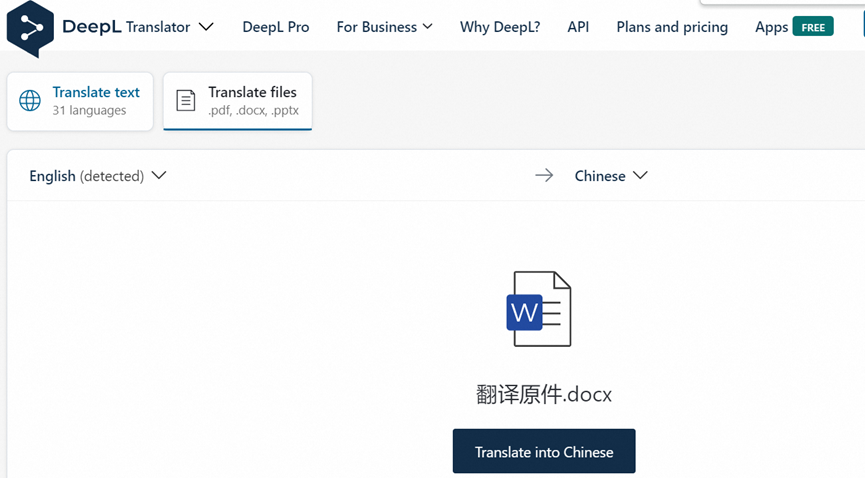
可以看到翻译很简单,上传一个word文件后,立刻就得到翻译件,特别适合篇幅比较大的文字的翻译 从最后的结果来看,翻译的准确度还是可以的,基本读的通,当然比不上母语水平,如果是母语水平要gpt4 以及需要分段粘贴,,
2,使用百度翻译
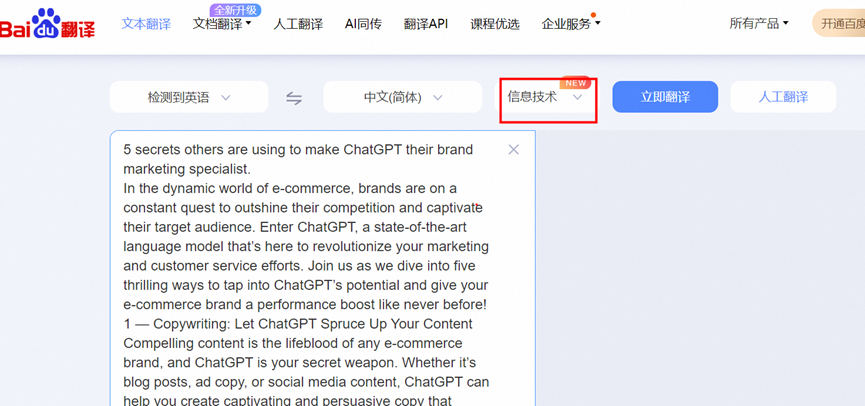
https://fanyi.baidu.com/?aldtype=16047#en/zh/
- 百度的优势是 有比较多的专业词库,可以使用不同行业的翻译模板,会替换专有名词,而且速度也很快,就是一次性只能翻译5000个字符
3 使用chatgpt
Chatgpt功能强大,众所周知,但是要最大的发挥出来,需要配合专业的prompt
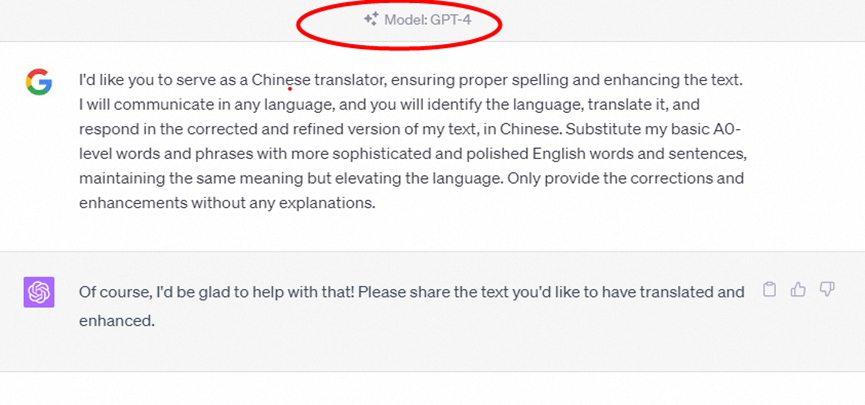
可以使用以下命令
I’d like you to serve as a Chinese translator, ensuring proper spelling and enhancing the text. I will communicate in any language, and you will identify the language, translate it, and respond in the corrected and refined version of my text, in Chinese. Substitute my basic A0-level words and phrases with more sophisticated and polished English words and sentences, maintaining the same meaning but elevating the language. Only provide the corrections and enhancements without any explanations.
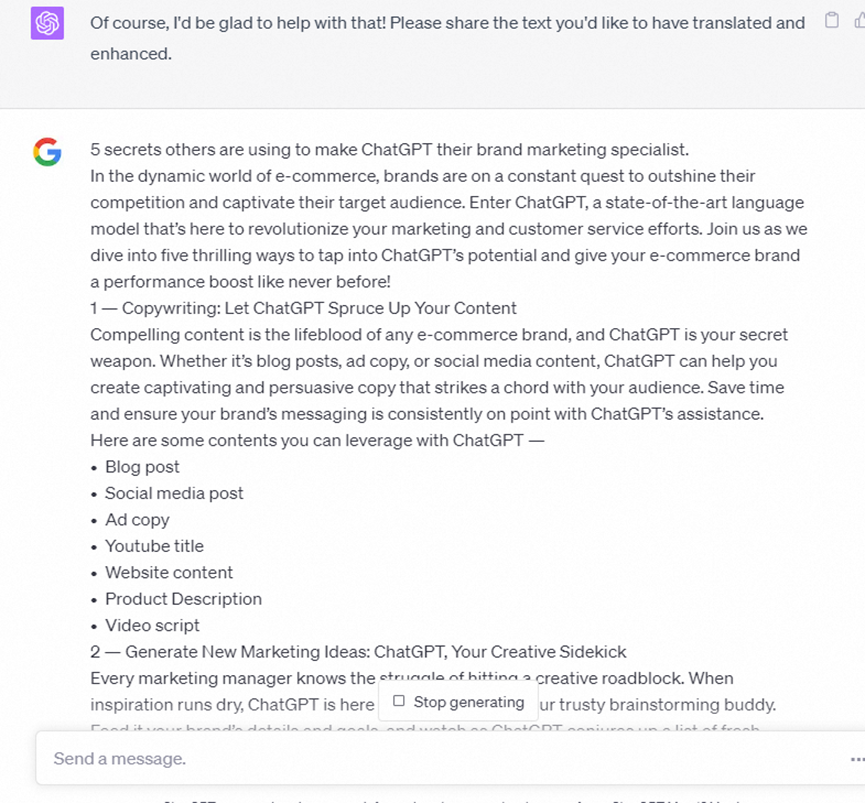
这段命令就是告诉gpt,要她扮演翻译者,然后保证流畅度以及适当的把低级词汇换成比较高级的,书面语,这样更加正式, 相比我们手动输入一段命令 帮我翻译下面的文字,缺少了细节,可能不如人意 以下截图是gpt4的翻译
很快()gpt3更快)就可以拿到答案,同理也可以使用gpt3 作为对比
最后对比下效果
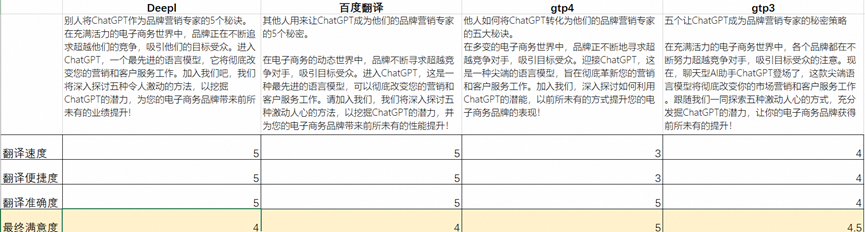
可以看到gpt4的翻译最完美,其次gpt3 也不错,百度翻译和deepl次之 需要说明的是,如果翻译的篇幅比较大,比如10页以上,还是建议deepl或者百度这样可以上传文档的,效率更好, 如果需要精度最大的,可以使用gpt4,分段输入,这时候她的精度最高
–彩蛋部分
本文是我手动写入的,但是很多地方可以优化词汇,所以我可以使用gpt帮我把这篇文章的文字润色,使用先命令
As a writing improvement assistant, your task is to improve the spelling, grammar, clarity, concision, and overall readability of the text provided, while breaking down long sentences, reducing repetition, and providing suggestions for improvement. Please provide only the corrected Chinese version of the text and avoid including explanations. I’ll send you the text later. If you understand, reply“明白”