2022年1月22日
| 标签:
新买的13pro,但是无法打开icloud,连接了wifi甚至是梯子,也无法解决
然后百度和谷歌了很多信息找到了解决方法
- 查看“系统状态”,确保当前没有影响 iCloud 的服务中断或计划维护。
- 确保断开所有配件的连接并取下保护壳。
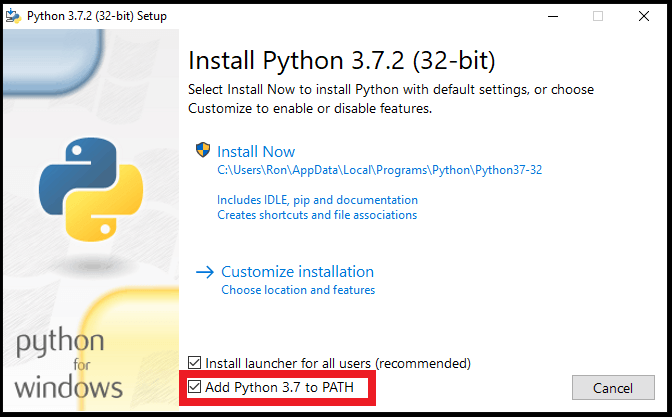
- 确保更新 iPhone 系统至最新。(重要:更新系统前,请备份 iPhone。)
- 确保您安装的 App 均来源于 App Store,并已更新至最新版本。
- 确保您的 iPhone 拥有足够的储存空间。
- 前往“设置”>“无线局域网”>“使用无线局域网与蜂窝网络的 App”,在“将数据用于”表单中,找到“设置”和“照片”,确保其选项均为“WLAN 与蜂窝网络”。
- 前往“设置”>“[您的姓名]”>“iCloud”>“照片”,尝试关闭“iCloud 照片”再重新打开,查看问题是否依然出现。
- 前往“设置”>“[您的姓名]”,尝试退出登录 Apple ID 并重新登录,查看问题是否依然出现。
- 轻点“设置”>“通用”>“还原”>“还原所有设置”。您的 iPhone 将重新启动,所有设置将会被移除,但不会抹除任何数据和媒体。
原理:主要是在wifi设置下 没有给相机和设置 这个功能权限,不得不得苹果的权限太严格了,对自家的功能都可以限制不上网,
最后解决
没有评论