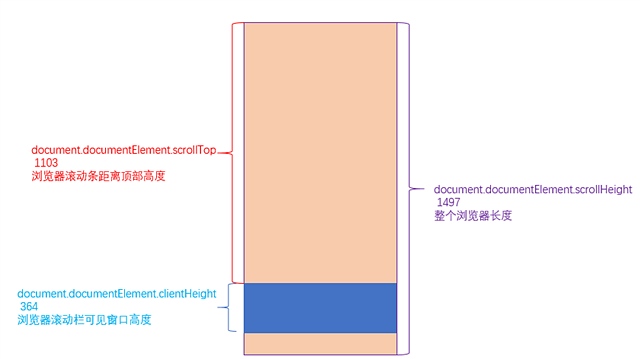
2019年11月9日
| 标签:
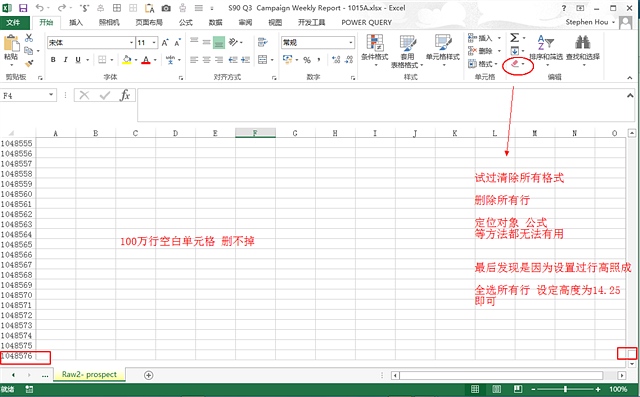
今天在处理Excel碰到一个很奇葩棘手的问题,一个空白单元簿 明明没有任何内容,但是缺有100多万行
导致整个excel文件非常大,虽然可以删除整个sheet来解决 本着刨根问底的精神以及如果这个表格里面有重要
信息不能删除 但是又发现表格内容很大 必须要处理的目的
经过网上搜索,试过了以下办法
使用快捷键ctr+shif+下 选择下面所有的行 去掉格式,删除行
都无法奏效
也试过定位单元格 查看是否含有隐藏的对象等也找不到
最后还是在excelhome里面的大神看到
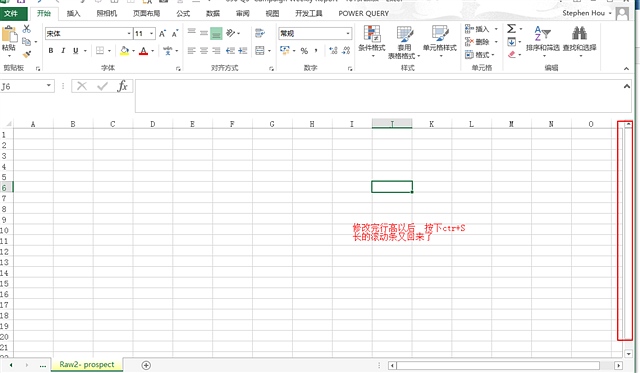
把所有的行高度设置为14.25 按下保存即可
果然就正常, 不得不佩服大神啊
总结
excel文件比较大,一定是有大量空白单元行,需要删除
传统的办法是去掉格式,在删除行即可(按下ctr+下即可知道是否删完)
但是有时候 如果设置了行高,这种办法是无效的 必须要把行高设置回默认值 行高14.25 或者查看新的表格的行高和列宽
这样excel才会 聪明的知道 这个单元格是没东西的(否则他会对行高恋恋不忘)

得到
今天在处理Excel碰到一个很奇葩棘手的问题,一个空白单元簿 明明没有任何内容,但是缺有100多万行
导致整个excel文件非常大,虽然可以删除整个sheet来解决 本着刨根问底的精神以及如果这个表格里面有重要
信息不能删除 但是又发现表格内容很大 必须要处理的目的
经过网上搜索,试过了以下办法
使用快捷键ctr+shif+下 选择下面所有的行 去掉格式,删除行
都无法奏效
也试过定位单元格 查看是否含有隐藏的对象等也找不到
最后还是在excelhome里面的大神看到
把所有的行高度设置为14.25 按下保存即可
果然就正常, 不得不佩服大神啊
总结
excel文件比较大,一定是有大量空白单元行,需要删除
传统的办法是去掉格式,在删除行即可(按下ctr+下即可知道是否删完)
但是有时候 如果设置了行高,这种办法是无效的 必须要把行高设置回默认值 行高14.25 或者查看新的表格的行高和列宽
这样excel才会 聪明的知道 这个单元格是没东西的(否则他会对行高恋恋不忘)
得到
没有评论