2019年11月5日
| 标签:
:
项目背景和调整
因为工作需要,要注册大量的论坛马甲小号,但是论坛的账号是需要邮箱去激活,我们没有那么多邮箱,如果先去注册一个邮箱再去注册一个论坛账号,非常费时
解决思路
我们其实需要的是一种类似万能邮箱,一次性生成大量生成注册大量邮箱账号,并且所有的邮箱收到激活邮件时会自动转到一个固定邮箱,方便我们去激活账号
解决方案
针对国外的论坛和国内的论坛发送来分 我们说下2种解决方案(国内的邮箱会收不到国外的论坛的激活信,最好是使用gmail等来注册,反之亦然)
海外论坛篇
经过检索我们发现,如果是需要大量的国外的邮箱账号(有些是国外论坛,用国内的邮箱是没有办法收到激活邮件) 就可以使用gmail的隐藏功能,既通过添加. 和+来实现
主要的原理是gmail其实是支持邮件字符串中任意位置可以加入. 以及尾部加+ 再加任意字符串 都代表邮件本身这隐藏设定来实现
具体是
注册一个gmail 邮箱 邮箱名字长点 如abcdefghijklm@gmail.com
gmail有个比较骚的操作就是可以在任意字符间加. 代表的是相同的邮箱 既
abcdefghijklm@gmail.com
a.bcdefghijklm@gmail.com
ab.cdefghijklm@gmail.com
abc.defghijklm@gmail.com
甚至是
abc.def.ghijklm@gmail.com
abc.def.g.hijklm@gmail.com
其实都是同一个邮箱
,并且gmail和googlemail这2个域名通用 既然
abc.def.ghijklm@gmail.com=abc.def.ghijklm@googlemail.com
但是加上. 其实邮箱个数还是有限的 如果是一个5位字符串的邮箱他的可能性只有十多种,还不算真正意义上的无限邮箱
其实Gmail还有一个隐藏功能既
还支持邮箱名称+ 任何字符串
如abc.def.ghijklm@gmail.com=abc.def.ghijklm+dfsdf45sdfdsf@gmail.com
既后面蓝色的字符是可以为任意,这样就可以生成真正意义上的无限邮箱
至于激活邮件 就只用进去你本身的gmail邮箱即可收取你的无限邮箱账号的邮件了
以上方法试用国外网站,国内网站会有2个问题, gmail邮箱可能会收不到,因为服务器在国外,反垃圾比较严格
这种情况后面可以用遨游魔术邮箱来解决,第2个是 有的网站不支持邮件名里面有. 和+
这种问题也可以使用遨游来解决
说完国外无限邮箱账号以后 我们在说下国内的解决方案
国内论坛篇
既然针对网站不能使用带点或者加号作为邮箱名称
可以考虑使用遨游的解决方法
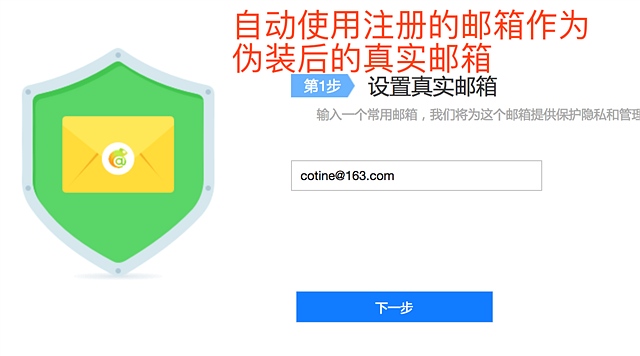
首先介绍下遨游的魔术邮箱原理
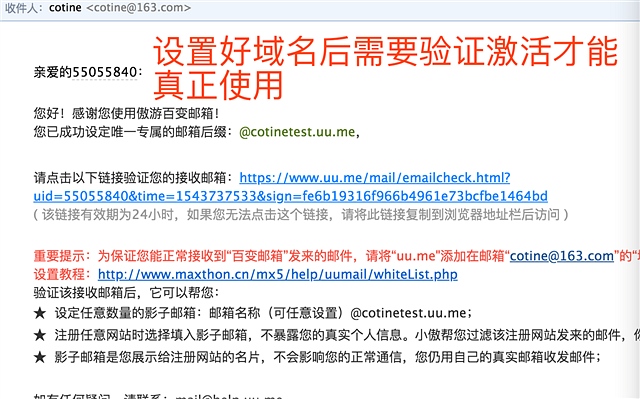
她其实是一个邮件中转器,既 为了隐藏自己的邮箱地址比如 ceo@baidu.com 这里可以使用ceo@abc.uu.me
这样的伪装邮箱来,这样就没人知道我是百度的CEO了,我要别人发到ceo@abc.uu.me的邮件自动被转发到 ceo@baidu.com,我就可以在网上大方的公布我的邮箱 而不用担心真实邮箱被知道, 并且
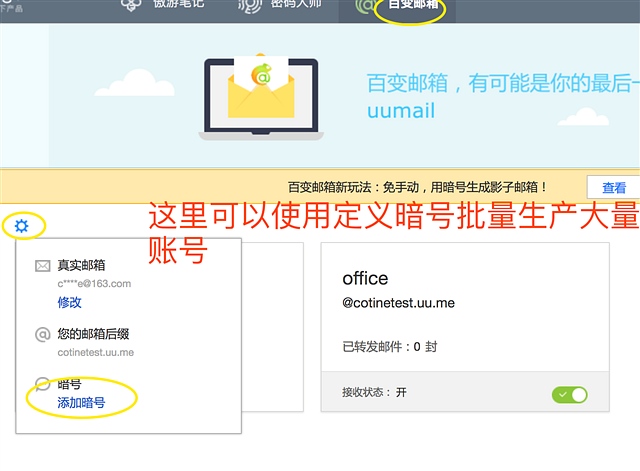
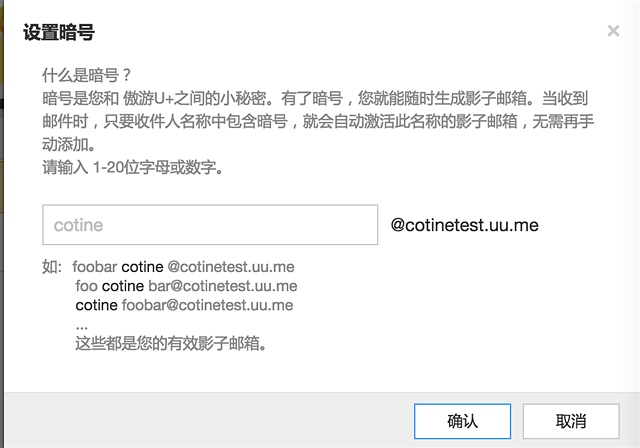
它还有一个功能 就是暗号 功能,如果我设置一个暗号 sina,那么 只要别人发送的邮箱名称中包含了sina
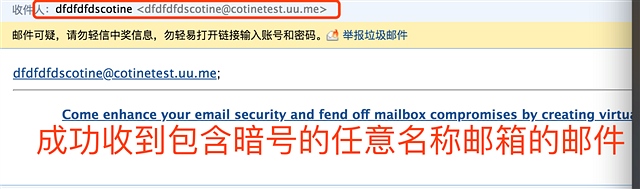
例如mingzisina@abc.uu.me,然后被发送到ceo@abc.uu.me 也就是我可以大量生产无限虚拟邮箱 但是背后都是同一个
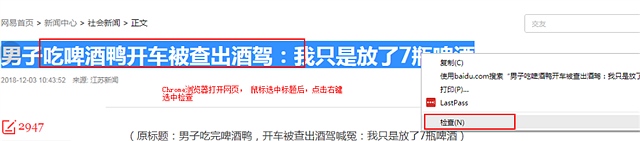
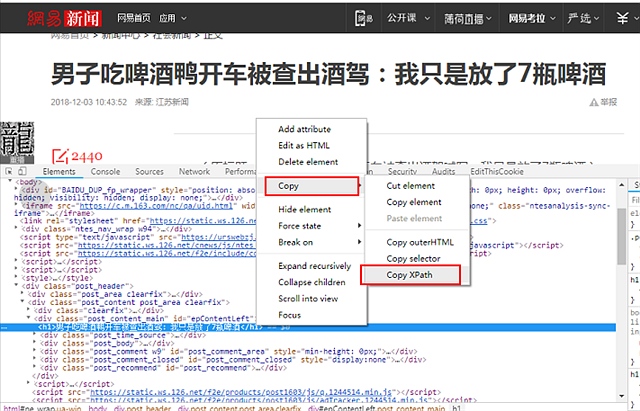
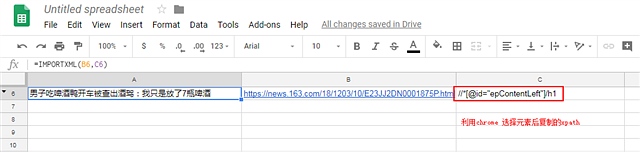
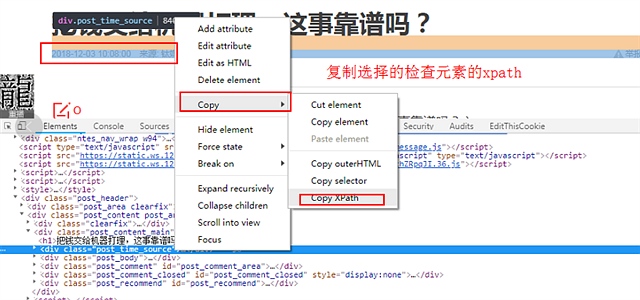
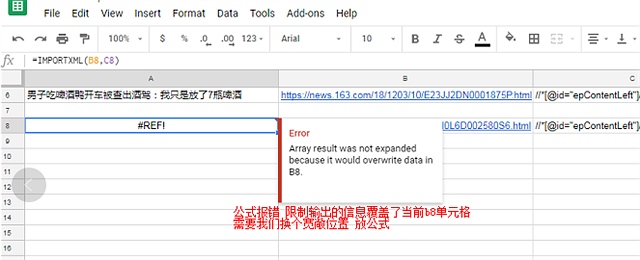
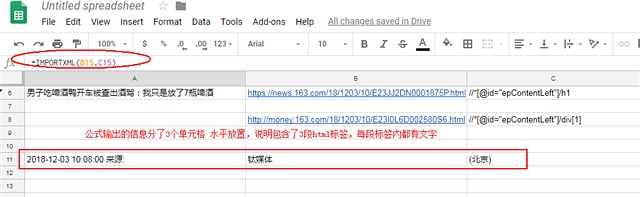
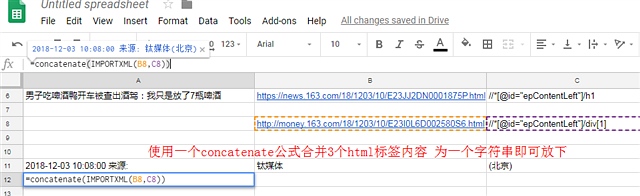
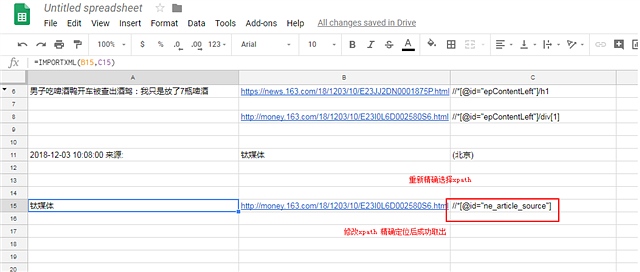
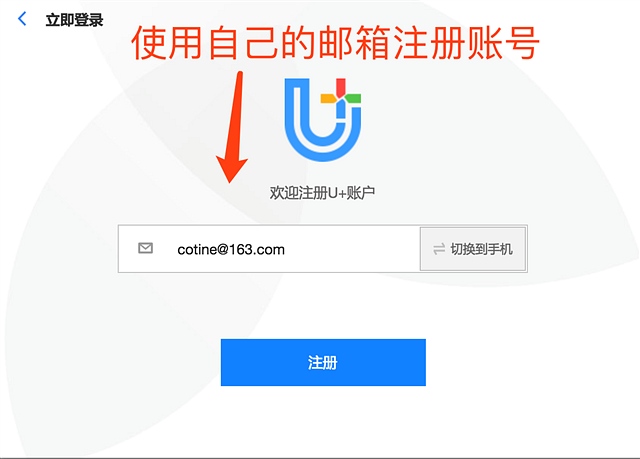
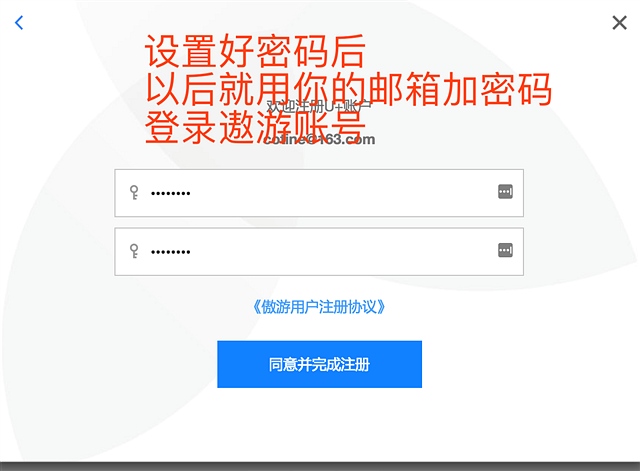
以下是截图过程
顺便吐槽和讯的IT 太久没更新浏览器的兼容性 Mac下 无法上传图片 只能盗图
直接访问: https://www.uu.me 按照提示步骤注册。



 写在最后 总结
写在最后 总结
本文介绍了2种 在短时间生产大量邮箱账号的办法,基本可以适用于所有普通的国外和国内论坛注册邮箱验证
这个方法的好处就是上手快,适用广 但是也有缺点就是如果有些论坛禁用了免费邮箱例如 qq 163 gmail 甚至是uu.me 这样的邮箱都不准用(有些论坛需要用公司邮箱注册,一般判断逻辑是排除所有市面上的免费邮箱,uu.me可能也会被封杀 如果知道的人多了)
并且这些邮箱最后的名称都不美观,如果我自己有一个公司域名 比如 www.alibaba.com 我希望生成大量的@alibaba.com邮箱并且 这些发送到这些大量邮箱的邮件都会转发到我私人邮箱 应该怎么做 我后文会有交代 生成无限邮件的终级方法
既利用企业邮箱加制定收信规则来生成大量自定义后缀的邮箱
终结方法比较繁琐 但是一劳永逸 因为使用遨游的解决方案 可能有一天遨游这个服务停了
但是需要购买一个域名 如果公司有域名就只需要配置下dns 然后这个方法需要点点技术基础
具体地址如下
http://cotine.blog.hexun.com/117780812_d.html
项目背景和调整
因为工作需要,要注册大量的论坛马甲小号,但是论坛的账号是需要邮箱去激活,我们没有那么多邮箱,如果先去注册一个邮箱再去注册一个论坛账号,非常费时
解决思路
我们其实需要的是一种类似万能邮箱,一次性生成大量生成注册大量邮箱账号,并且所有的邮箱收到激活邮件时会自动转到一个固定邮箱,方便我们去激活账号
解决方案
针对国外的论坛和国内的论坛发送来分 我们说下2种解决方案(国内的邮箱会收不到国外的论坛的激活信,最好是使用gmail等来注册,反之亦然)
海外论坛篇
经过检索我们发现,如果是需要大量的国外的邮箱账号(有些是国外论坛,用国内的邮箱是没有办法收到激活邮件) 就可以使用gmail的隐藏功能,既通过添加. 和+来实现
主要的原理是gmail其实是支持邮件字符串中任意位置可以加入. 以及尾部加+ 再加任意字符串 都代表邮件本身这隐藏设定来实现
具体是
注册一个gmail 邮箱 邮箱名字长点 如abcdefghijklm@gmail.com
gmail有个比较骚的操作就是可以在任意字符间加. 代表的是相同的邮箱 既
abcdefghijklm@gmail.com
a.bcdefghijklm@gmail.com
ab.cdefghijklm@gmail.com
abc.defghijklm@gmail.com
甚至是
abc.def.ghijklm@gmail.com
abc.def.g.hijklm@gmail.com
其实都是同一个邮箱
,并且gmail和googlemail这2个域名通用 既然
abc.def.ghijklm@gmail.com=abc.def.ghijklm@googlemail.com
但是加上. 其实邮箱个数还是有限的 如果是一个5位字符串的邮箱他的可能性只有十多种,还不算真正意义上的无限邮箱
其实Gmail还有一个隐藏功能既
还支持邮箱名称+ 任何字符串
如abc.def.ghijklm@gmail.com=abc.def.ghijklm+dfsdf45sdfdsf@gmail.com
既后面蓝色的字符是可以为任意,这样就可以生成真正意义上的无限邮箱
至于激活邮件 就只用进去你本身的gmail邮箱即可收取你的无限邮箱账号的邮件了
以上方法试用国外网站,国内网站会有2个问题, gmail邮箱可能会收不到,因为服务器在国外,反垃圾比较严格
这种情况后面可以用遨游魔术邮箱来解决,第2个是 有的网站不支持邮件名里面有. 和+
这种问题也可以使用遨游来解决
说完国外无限邮箱账号以后 我们在说下国内的解决方案
国内论坛篇
既然针对网站不能使用带点或者加号作为邮箱名称
可以考虑使用遨游的解决方法
首先介绍下遨游的魔术邮箱原理
她其实是一个邮件中转器,既 为了隐藏自己的邮箱地址比如 ceo@baidu.com 这里可以使用ceo@abc.uu.me
这样的伪装邮箱来,这样就没人知道我是百度的CEO了,我要别人发到ceo@abc.uu.me的邮件自动被转发到 ceo@baidu.com,我就可以在网上大方的公布我的邮箱 而不用担心真实邮箱被知道, 并且
它还有一个功能 就是暗号 功能,如果我设置一个暗号 sina,那么 只要别人发送的邮箱名称中包含了sina
例如mingzisina@abc.uu.me,然后被发送到ceo@abc.uu.me 也就是我可以大量生产无限虚拟邮箱 但是背后都是同一个
以下是截图过程
顺便吐槽和讯的IT 太久没更新浏览器的兼容性 Mac下 无法上传图片 只能盗图
直接访问: https://www.uu.me 按照提示步骤注册。
写在最后 总结
本文介绍了2种 在短时间生产大量邮箱账号的办法,基本可以适用于所有普通的国外和国内论坛注册邮箱验证
这个方法的好处就是上手快,适用广 但是也有缺点就是如果有些论坛禁用了免费邮箱例如 qq 163 gmail 甚至是uu.me 这样的邮箱都不准用(有些论坛需要用公司邮箱注册,一般判断逻辑是排除所有市面上的免费邮箱,uu.me可能也会被封杀 如果知道的人多了)
并且这些邮箱最后的名称都不美观,如果我自己有一个公司域名 比如 www.alibaba.com 我希望生成大量的@alibaba.com邮箱并且 这些发送到这些大量邮箱的邮件都会转发到我私人邮箱 应该怎么做 我后文会有交代 生成无限邮件的终级方法
既利用企业邮箱加制定收信规则来生成大量自定义后缀的邮箱
终结方法比较繁琐 但是一劳永逸 因为使用遨游的解决方案 可能有一天遨游这个服务停了
但是需要购买一个域名 如果公司有域名就只需要配置下dns 然后这个方法需要点点技术基础
具体地址如下
http://cotine.blog.hexun.com/117780812_d.html
没有评论