
网页抓取任意元素之利用Google Chrome通过xpath获取网页的html元素及调试
2019年11月6日
| 标签:
网页抓取任意元素之利用Google Chrome通过xpath获取网页的html元素及调试
标题有点拗口,其实主要是这样的一个场景,我们需要抓取某个页面的某一个元素,一般流程是需要仔细分析这个元素的代码结构,各种查找 替换 才能提取, 那么有没有比较简单的方法 但是是xpath

这种语言是利用xml的结构化语言,来选取 具体基本知识可以去w3c网站上查
基本就是//div 表示查找页面里面每一个div元素,//div[@id=”12″] 表示查找div 并且其属性id为12的元素
//div[@id=”12″]/div[2] 表示查找div 并且其属性id为12的元素下面包含的若干div的中的第3个div
我们举个例子
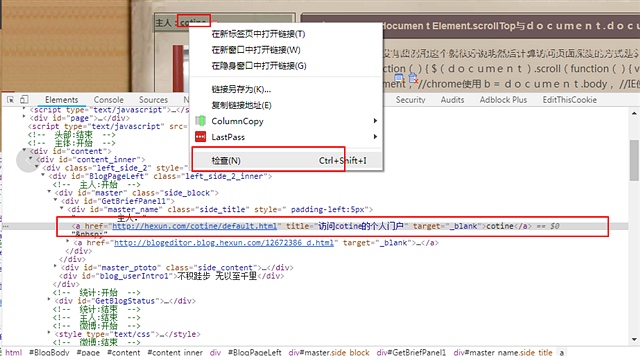
打开我的博客首页cotine.hexun.com 按下chrome的F12, 可以打开网页调试面板
我们想抓取我左边的博客名称 cotine ,
在cotine上门点击右键,选择审查 下方的调试面板会高亮显示这块代码
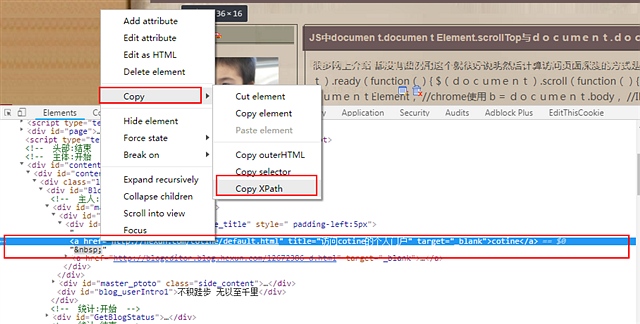
在下方代码这块我们再点右键
选择复制xpath 即可获得
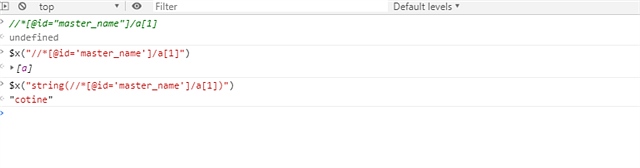
然后我们按下esc 或者点击console 进去控制台
使用控制台命令
$x(””)
引号中输入我们复制的xpath 需要注意是是 xpath中的双引号要换成单引号
这点新手很容易错
就可以获得这个节点的信息 及a对象
我们使用string 函数或者这个对象中所有的值
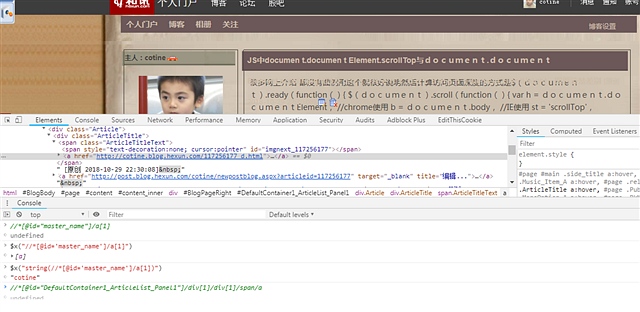
掌握了这个方法 我们可以获得第一个博客的标题
点击标题后选择审查后在下方代码中 选择copy xpath
网页抓取任意元素之利用Google Chrome通过xpath获取网页的html元素及调试
标题有点拗口,其实主要是这样的一个场景,我们需要抓取某个页面的某一个元素,一般流程是需要仔细分析这个元素的代码结构,各种查找 替换 才能提取, 那么有没有比较简单的方法 但是是xpath
这种语言是利用xml的结构化语言,来选取 具体基本知识可以去w3c网站上查
基本就是//div 表示查找页面里面每一个div元素,//div[@id=”12″] 表示查找div 并且其属性id为12的元素
//div[@id=”12″]/div[2] 表示查找div 并且其属性id为12的元素下面包含的若干div的中的第3个div
我们举个例子
打开我的博客首页cotine.hexun.com 按下chrome的F12, 可以打开网页调试面板
我们想抓取我左边的博客名称 cotine ,
在cotine上门点击右键,选择审查 下方的调试面板会高亮显示这块代码
在下方代码这块我们再点右键
选择复制xpath 即可获得
然后我们按下esc 或者点击console 进去控制台
使用控制台命令
$x(””)
引号中输入我们复制的xpath 需要注意是是 xpath中的双引号要换成单引号
这点新手很容易错
就可以获得这个节点的信息 及a对象
我们使用string 函数或者这个对象中所有的值
掌握了这个方法 我们可以获得第一个博客的标题
点击标题后选择审查后在下方代码中 选择copy xpath
发表评论
| Trackback
