2019年9月3日
| 标签:
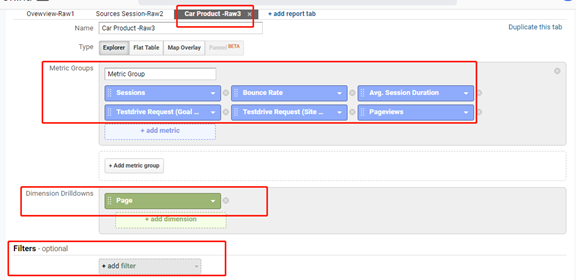
背景介绍
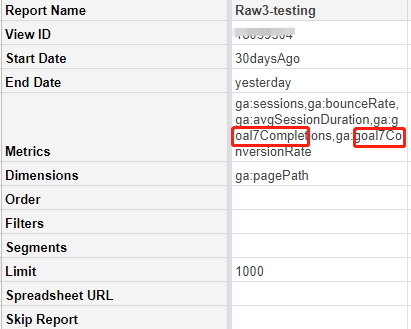
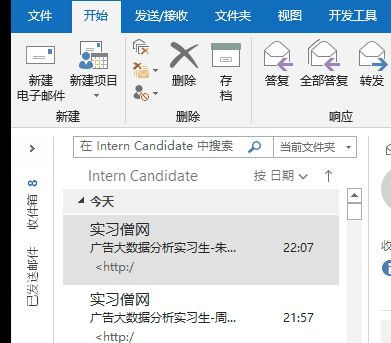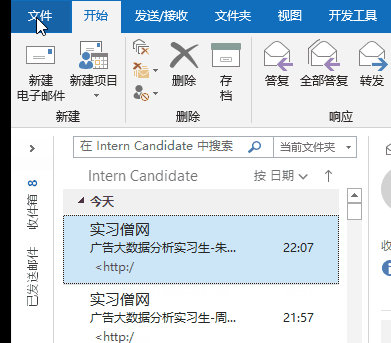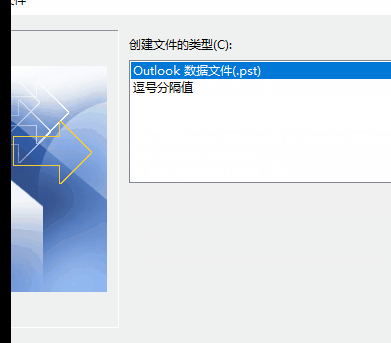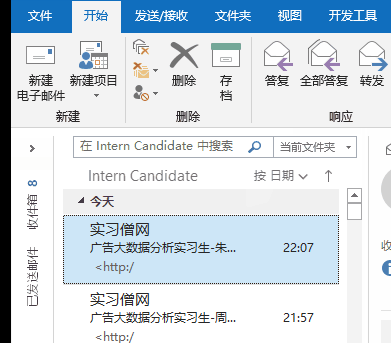
最近公司招新实习生,在实习僧网站投放招聘信息以后,收到大量的学生的邮件,3天时间收到300多封
我们需要安排学校 学历(研究生 本科)毕业年级(今年或者明年)进行筛选
想着就是把邮件的信息复制到excel中 在进行各种筛选
但是一个手工复制到excel不现实
所以想着有什么方便的办法把 批量把outlook中的邮件中文复制到excel
解决方法
先想着使用了vba的办法,但是每次只能粘贴了几十个就不行了
就是不知道原因
然后无意间看到outlook有导出到excel的功能 可以包含邮件的正文
这样再用excel的提取字符串命令即可
下面是视频的方法
也可以使用百度搜索 outlook 导出到csv即可
关键是思路
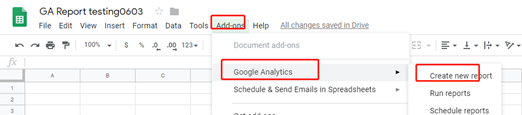
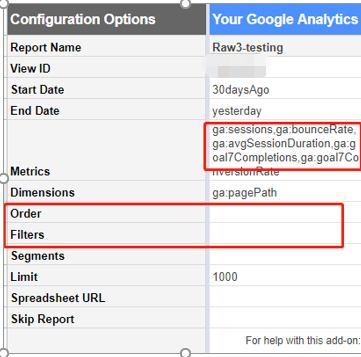
点击outlook上方的文件
选择打开或导出
选择要导出的文件夹(可以提前 使用搜索命令 把要导出的文件放到临时文件夹中)
然后导出到csv文件
这个csv文件要使用excel打开 否则会事乱码哦
最后使用excel的find命令查找特征字符串的位置 再使用mid命令
截取我们需要的字符串
背景介绍
最近公司招新实习生,在实习僧网站投放招聘信息以后,收到大量的学生的邮件,3天时间收到300多封
我们需要安排学校 学历(研究生 本科)毕业年级(今年或者明年)进行筛选
想着就是把邮件的信息复制到excel中 在进行各种筛选
但是一个手工复制到excel不现实
所以想着有什么方便的办法把 批量把outlook中的邮件中文复制到excel
解决方法
先想着使用了vba的办法,但是每次只能粘贴了几十个就不行了
就是不知道原因
然后无意间看到outlook有导出到excel的功能 可以包含邮件的正文
这样再用excel的提取字符串命令即可
下面是视频的方法
也可以使用百度搜索 outlook 导出到csv即可
关键是思路
点击outlook上方的文件
选择打开或导出
选择要导出的文件夹(可以提前 使用搜索命令 把要导出的文件放到临时文件夹中)
然后导出到csv文件
这个csv文件要使用excel打开 否则会事乱码哦
最后使用excel的find命令查找特征字符串的位置 再使用mid命令
截取我们需要的字符串
没有评论