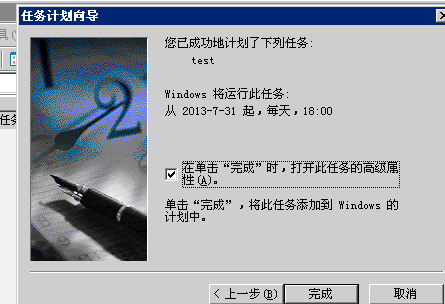
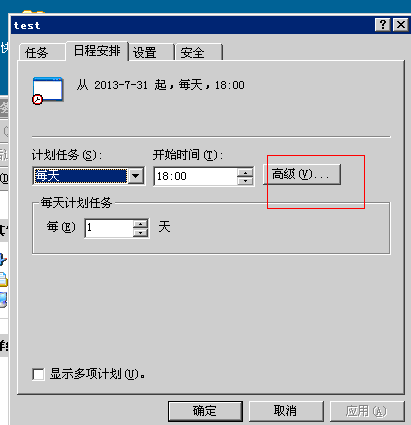
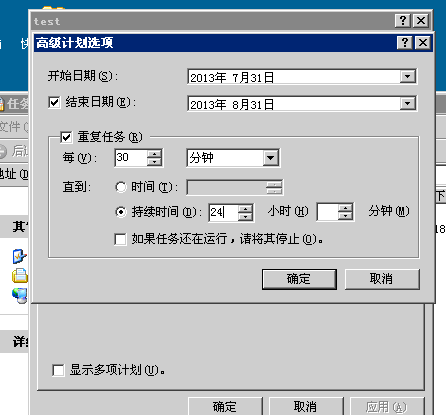
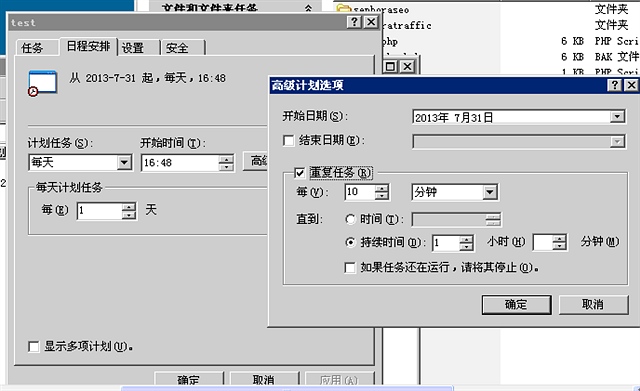
:
先看效果
| www.xcar.com.cn |
| www.pcauto.com.cn |
| www.jimi168.com |
| www.feelcars.com |
| www.chinaunix.net |
| www.cheshi.com |
| www.app111.com |
| auto.sohu.com |
| auto.sina.com.cn |
| auto.people.com.cn |
| auto.msn.com.cn |
| auto.china.com |
| auto.163.com |
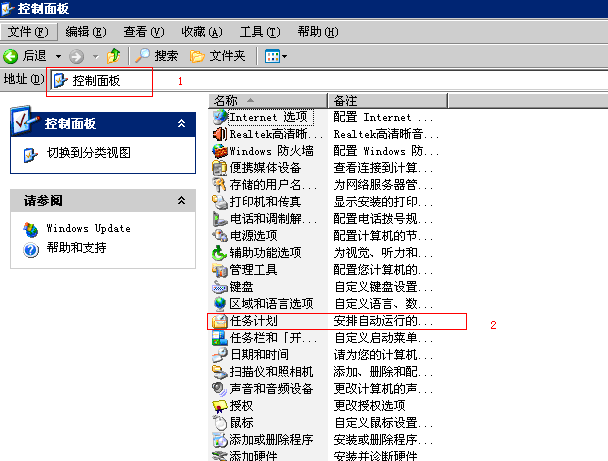
抓取这13个网站
我使用了curl 单线程抓取 所有内容然后放入变量中
耗时是33秒
然后我使用curl的多线程抓取 然后放置内容到函数中 用事是8秒 速度快了4倍以上 平均1秒可以分析2个网页
这还是在网速很卡的情况下
所以可以预估的是
如果是我多线程 设置好参数 查询13个社交平台的数据进行分析 是可以在3秒之内完成结果的
我们先进行打基数
直接看代码
先是单线程代码
<?php
$curl = curl_init();// 初始化一个 cURL 对象
curl_setopt($curl, CURLOPT_URL, ‘http://www.163.com’);// 设置你需要抓取的URL
curl_setopt($curl, CURLOPT_HEADER, 0);// 设置header
curl_setopt($curl, CURLOPT_USERAGENT, “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36”); //直接用chrome的开发工具打开网页然后抄下你的发送的request中agent参数
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);// 设置cURL 参数,要求结果保存到字符串中如果是0就是直接打印在频幕上 如果不设置就直接打印在屏幕上 这里我们需要保存在字符串所以是true。
$data = curl_exec($curl);// 运行cURL,请求网页
curl_close($curl);// 关闭URL请求 释放内存
echo $data;// 显示获得的数据
?>
上面就是最简单的例子 获取网页 然后复制到变量 再显示网页上
需要主要就是returntransfer要设置为1 确保返回给变量 然后就是agent数据要用chrome里面查询到的
关于更多的setopt 可以这里查询
http://php.net/manual/zh/function.curl-setopt.php
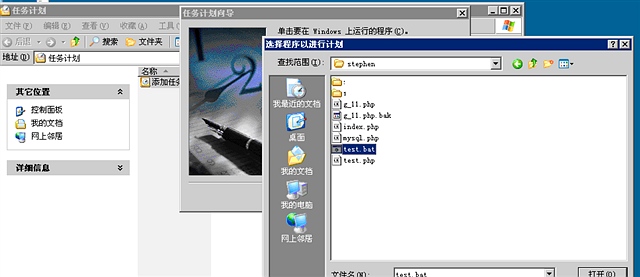
然后我们做一个循环 查询13个网站
<?php
$urls = array(
‘www.xcar.com.cn’,
‘www.pcauto.com.cn’,
‘www.jimi168.com’,
‘www.feelcars.com’,
‘www.chinaunix.net’,
‘www.cheshi.com’,
‘www.app111.com’,
‘auto.sohu.com’,
‘auto.sina.com.cn’,
‘auto.people.com.cn’,
‘auto.msn.com.cn’,
‘auto.china.com’,
‘auto.163.com’
);
$curl = curl_init();
//开始计时,放在头部
$pagestartime=microtime();
foreach($urls as $url){
// 初始化一个 cURL 对象
// 设置你需要抓取的URL
curl_setopt($curl, CURLOPT_URL, $url);
// 设置header
curl_setopt($curl, CURLOPT_HEADER, 0);
// 设置cURL 参数,要求结果保存到字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_USERAGENT, “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36”);
// 设置cURL 参数,要求结果保存到字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
// 运行cURL,请求网页
$data = curl_exec($curl);
@$totaldata=$totaldata.$data;
}
// 关闭URL请求
curl_close($curl);
//结束计时,放在最底部
$pageendtime = microtime();
$starttime = explode(” “,$pagestartime);
$endtime = explode(” “,$pageendtime);
$totaltime = $endtime[0]-$starttime[0]+$endtime[1]-$starttime[1];
$timecost = sprintf(“%s”,$totaltime);
echo “页面运行时间: $timecost seconds”;
echo $totaldata;
?>
这里我们使用了计时器 查看查询这些网址并且赋值给变量要多久
需要注意的是先输出时间 再输出html源代码 否则源代码这么长 显示出来要等很久
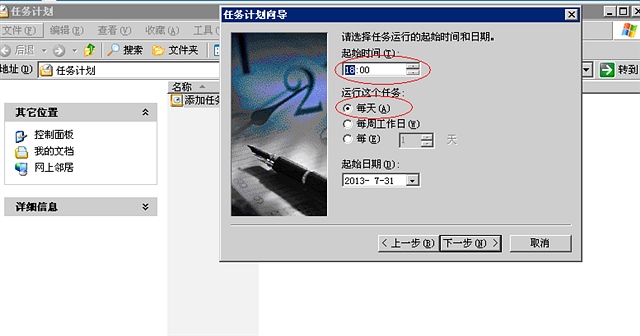
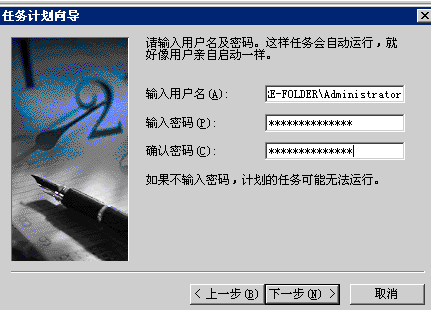
再看看使用curl的多线程的方法
<html>
<meta charset=”gb2312″>
<?php
set_time_limit(0);
//开始计时,放在头部
$pagestartime=microtime();
$urls = array(
‘www.xcar.com.cn’,
‘www.pcauto.com.cn’,
‘www.jimi168.com’,
‘www.feelcars.com’,
‘www.chinaunix.net’,
‘www.cheshi.com’,
‘www.app111.com’,
‘auto.sohu.com’,
‘auto.sina.com.cn’,
‘auto.people.com.cn’,
‘auto.msn.com.cn’,
‘auto.china.com’,
‘auto.163.com’
);
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36”);
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,1); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
@$totaldata=$totaldata.$data;
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
//结束计时,放在最底部
$pageendtime = microtime();
$starttime = explode(” “,$pagestartime);
$endtime = explode(” “,$pageendtime);
$totaltime = $endtime[0]-$starttime[0]+$endtime[1]-$starttime[1];
$timecost = sprintf(“%s”,$totaltime);
echo “页面运行时间: $timecost seconds”;
echo $totaldata;
?>
</html>
先看效果
| www.xcar.com.cn |
| www.pcauto.com.cn |
| www.jimi168.com |
| www.feelcars.com |
| www.chinaunix.net |
| www.cheshi.com |
| www.app111.com |
| auto.sohu.com |
| auto.sina.com.cn |
| auto.people.com.cn |
| auto.msn.com.cn |
| auto.china.com |
| auto.163.com |
抓取这13个网站
我使用了curl 单线程抓取 所有内容然后放入变量中
耗时是33秒
然后我使用curl的多线程抓取 然后放置内容到函数中 用事是8秒 速度快了4倍以上 平均1秒可以分析2个网页
这还是在网速很卡的情况下
所以可以预估的是
如果是我多线程 设置好参数 查询13个社交平台的数据进行分析 是可以在3秒之内完成结果的
我们先进行打基数
直接看代码
先是单线程代码
<?php
$curl = curl_init();// 初始化一个 cURL 对象
curl_setopt($curl, CURLOPT_URL, ‘http://www.163.com’);// 设置你需要抓取的URL
curl_setopt($curl, CURLOPT_HEADER, 0);// 设置header
curl_setopt($curl, CURLOPT_USERAGENT, “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36”); //直接用chrome的开发工具打开网页然后抄下你的发送的request中agent参数
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);// 设置cURL 参数,要求结果保存到字符串中如果是0就是直接打印在频幕上 如果不设置就直接打印在屏幕上 这里我们需要保存在字符串所以是true。
$data = curl_exec($curl);// 运行cURL,请求网页
curl_close($curl);// 关闭URL请求 释放内存
echo $data;// 显示获得的数据
?>
上面就是最简单的例子 获取网页 然后复制到变量 再显示网页上
需要主要就是returntransfer要设置为1 确保返回给变量 然后就是agent数据要用chrome里面查询到的
关于更多的setopt 可以这里查询
http://php.net/manual/zh/function.curl-setopt.php
然后我们做一个循环 查询13个网站
<?php
$urls = array(
‘www.xcar.com.cn’,
‘www.pcauto.com.cn’,
‘www.jimi168.com’,
‘www.feelcars.com’,
‘www.chinaunix.net’,
‘www.cheshi.com’,
‘www.app111.com’,
‘auto.sohu.com’,
‘auto.sina.com.cn’,
‘auto.people.com.cn’,
‘auto.msn.com.cn’,
‘auto.china.com’,
‘auto.163.com’
);
$curl = curl_init();
//开始计时,放在头部
$pagestartime=microtime();
foreach($urls as $url){
// 初始化一个 cURL 对象
// 设置你需要抓取的URL
curl_setopt($curl, CURLOPT_URL, $url);
// 设置header
curl_setopt($curl, CURLOPT_HEADER, 0);
// 设置cURL 参数,要求结果保存到字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_USERAGENT, “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36”);
// 设置cURL 参数,要求结果保存到字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
// 运行cURL,请求网页
$data = curl_exec($curl);
@$totaldata=$totaldata.$data;
}
// 关闭URL请求
curl_close($curl);
//结束计时,放在最底部
$pageendtime = microtime();
$starttime = explode(” “,$pagestartime);
$endtime = explode(” “,$pageendtime);
$totaltime = $endtime[0]-$starttime[0]+$endtime[1]-$starttime[1];
$timecost = sprintf(“%s”,$totaltime);
echo “页面运行时间: $timecost seconds”;
echo $totaldata;
?>
这里我们使用了计时器 查看查询这些网址并且赋值给变量要多久
需要注意的是先输出时间 再输出html源代码 否则源代码这么长 显示出来要等很久
再看看使用curl的多线程的方法
<html>
<meta charset=”gb2312″>
<?php
set_time_limit(0);
//开始计时,放在头部
$pagestartime=microtime();
$urls = array(
‘www.xcar.com.cn’,
‘www.pcauto.com.cn’,
‘www.jimi168.com’,
‘www.feelcars.com’,
‘www.chinaunix.net’,
‘www.cheshi.com’,
‘www.app111.com’,
‘auto.sohu.com’,
‘auto.sina.com.cn’,
‘auto.people.com.cn’,
‘auto.msn.com.cn’,
‘auto.china.com’,
‘auto.163.com’
);
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36”);
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,1); // 设置不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
@$totaldata=$totaldata.$data;
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
//结束计时,放在最底部
$pageendtime = microtime();
$starttime = explode(” “,$pagestartime);
$endtime = explode(” “,$pageendtime);
$totaltime = $endtime[0]-$starttime[0]+$endtime[1]-$starttime[1];
$timecost = sprintf(“%s”,$totaltime);
echo “页面运行时间: $timecost seconds”;
echo $totaldata;
?>
</html>